|
|
@@ -21,7 +21,7 @@ In short, low-code platforms are not meant to replace code but provide a higher
|
|
|
|
|
|
### 5.1.2 Choosing a Low-Code Platform
|
|
|
|
|
|
-Currently, the low-code platform market for agents and LLM applications presents a flourishing situation, with each platform having its unique positioning and advantages. Which platform to choose often depends on your core needs, technical background, and the ultimate goal of the project. In the subsequent content of this chapter, we will focus on introducing and practicing three representative platforms: Coze, Dify, and n8n. Before that, let's give them a brief introduction.
|
|
|
+Currently, the low-code platform market for agents and LLM applications presents a flourishing situation, with each platform having its unique positioning and advantages. Which platform to choose often depends on your core needs, technical background, and the ultimate goal of the project. In the subsequent content of this chapter, we will focus on introducing and practicing several representative platforms: Coze, Dify, FastGPT, and n8n. Before that, let's give them a brief introduction.
|
|
|
|
|
|
**Coze**
|
|
|
|
|
|
@@ -35,9 +35,15 @@ Currently, the low-code platform market for agents and LLM applications presents
|
|
|
- **Feature Analysis**: It integrates the concepts of backend services and model operations, supporting multiple capabilities such as Agent workflows, RAG Pipeline, data annotation, and fine-tuning. For enterprise-level applications pursuing professionalism, stability, and scalability, Dify provides a solid foundation.
|
|
|
- **Target Audience**: Developers with some technical background, teams that need to build scalable enterprise-level AI applications.
|
|
|
|
|
|
+**FastGPT**
|
|
|
+
|
|
|
+- **Core Positioning**: FastGPT is an open-source, LLM-based knowledge base Q&A platform and Agent building tool<sup>[3]</sup>, focusing on providing easy-to-use RAG (Retrieval-Augmented Generation) solutions and visual workflow orchestration capabilities.
|
|
|
+- **Feature Analysis**: FastGPT's core advantage lies in its extreme optimization for knowledge base Q&A scenarios. It provides a complete RAG pipeline from data import, automatic text chunking, vectorized storage to intelligent retrieval, and supports orchestrating complex conversation flows and Agent workflows through an intuitive visual interface (Flow module). The platform adopts a model-neutral design, flexibly connecting to various mainstream domestic and international large models such as OpenAI, Claude, and Tongyi Qianwen, while providing comprehensive API interfaces and a plugin market for quick integration with existing systems like WeChat Work, DingTalk, and Feishu.
|
|
|
+- **Target Audience**: Developers and small-to-medium enterprise teams who want to quickly build intelligent customer service, internal knowledge assistants, or document Q&A robots based on private knowledge bases, as well as technology enthusiasts interested in RAG who wish to lower the implementation barrier.
|
|
|
+
|
|
|
**n8n**
|
|
|
|
|
|
-- **Core Positioning**: n8n is essentially an open-source workflow automation tool<sup>[3]</sup>, not a pure LLM platform. In recent years, it has actively integrated AI capabilities.
|
|
|
+- **Core Positioning**: n8n is essentially an open-source workflow automation tool<sup>[4]</sup>, not a pure LLM platform. In recent years, it has actively integrated AI capabilities.
|
|
|
|
|
|
- **Feature Analysis**: n8n's strength lies in "connection." It has hundreds of preset nodes that can easily connect various SaaS services, databases, and APIs into complex automated business processes. You can embed LLM nodes in this process, making it part of the entire automation chain. Although it is not as specialized in LLM functionality as the first two, its general automation capability is unique. However, its learning curve is also relatively steep.
|
|
|
|
|
|
@@ -290,7 +296,7 @@ Furthermore, we can click this [experience link](https://www.coze.cn/store/proje
|
|
|
|
|
|
* **Does Not Support MCP:** I think this is the most fatal. Although Coze's plugin market is extremely rich and attractive, not supporting MCP may become a shackle limiting its development. If opened up, it will be another killer feature.
|
|
|
* **High Complexity of Some Plugin Configurations:** For plugins that require API Keys or other advanced parameters, users may need some technical background to complete correct configuration. Complex workflow orchestration is also not something that can be mastered with zero foundation; it requires some JavaScript or Python basics.
|
|
|
- * **Unable to import JSON files:** Previously, the app didn't have an export/import function, but the paid version now does. However, the exported/imported file isn't a JSON file like Dify or N8n; it's a ZIP file. This means you can only export from the app and then import the ZIP file. However, you can use a workaround: in the layout interface, press Ctrl+A to select all, then Ctrl+C to copy the layout, and then paste it into another blank workflow or other workflows.
|
|
|
+ * **Unable to directly import JSON files:** Previously, the app didn't have an export/import function, but the paid version now does. However, the exported/imported file isn't a JSON file like Dify or N8n; it's a ZIP file. This means you can only export from the app and then import the ZIP file. However, you can use a workaround: in the layout interface, press Ctrl+A to select all, then Ctrl+C to copy the layout, and then paste it into another blank workflow or other workflows.
|
|
|
|
|
|
|
|
|
## 5.3 Platform Two: Dify
|
|
|
@@ -515,14 +521,16 @@ The effect demonstration is shown in Figure 5.27:
|
|
|
|
|
|
**Multimodal Generation Module**
|
|
|
|
|
|
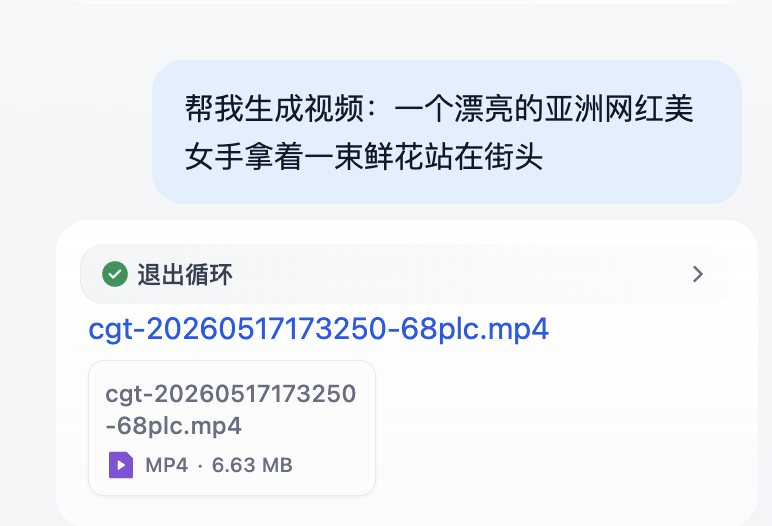
-Image and video generation is another high-frequency application scenario. With the evolution of models like Doubao image generation and Google Imagen, as well as breakthroughs in video generation technologies like Keling, Google Veo 3, and OpenAI Sora 2, the quality of multimodal content generation has reached a practical level.
|
|
|
+Image and video generation is another high-frequency application scenario. With the evolution of models like Jimeng image generation and Google Imagen, as well as breakthroughs in video generation technologies like Keling, Google Veo 3, seedance2.0, and OpenAI Sora 2, the quality of multimodal content generation has reached a practical level.
|
|
|
|
|
|
-This case uses the Doubao plugin to implement image and video generation. Configuration steps are as follows:
|
|
|
+This case uses the Jimeng plugin to implement image and video generation. Configuration steps are as follows:
|
|
|
|
|
|
-1. Add Doubao image/video generation plugin in the workflow
|
|
|
-2. Configure parameters (such as image ratio 1:1, model selection doubao seedream)
|
|
|
+1. Add Jimeng image/video generation plugin in the workflow
|
|
|
+2. Configure parameters (such as image ratio 1:1, model selection seedream4.5/5.0 and seedance1.5/2.0)
|
|
|
3. Output the generated file
|
|
|
|
|
|
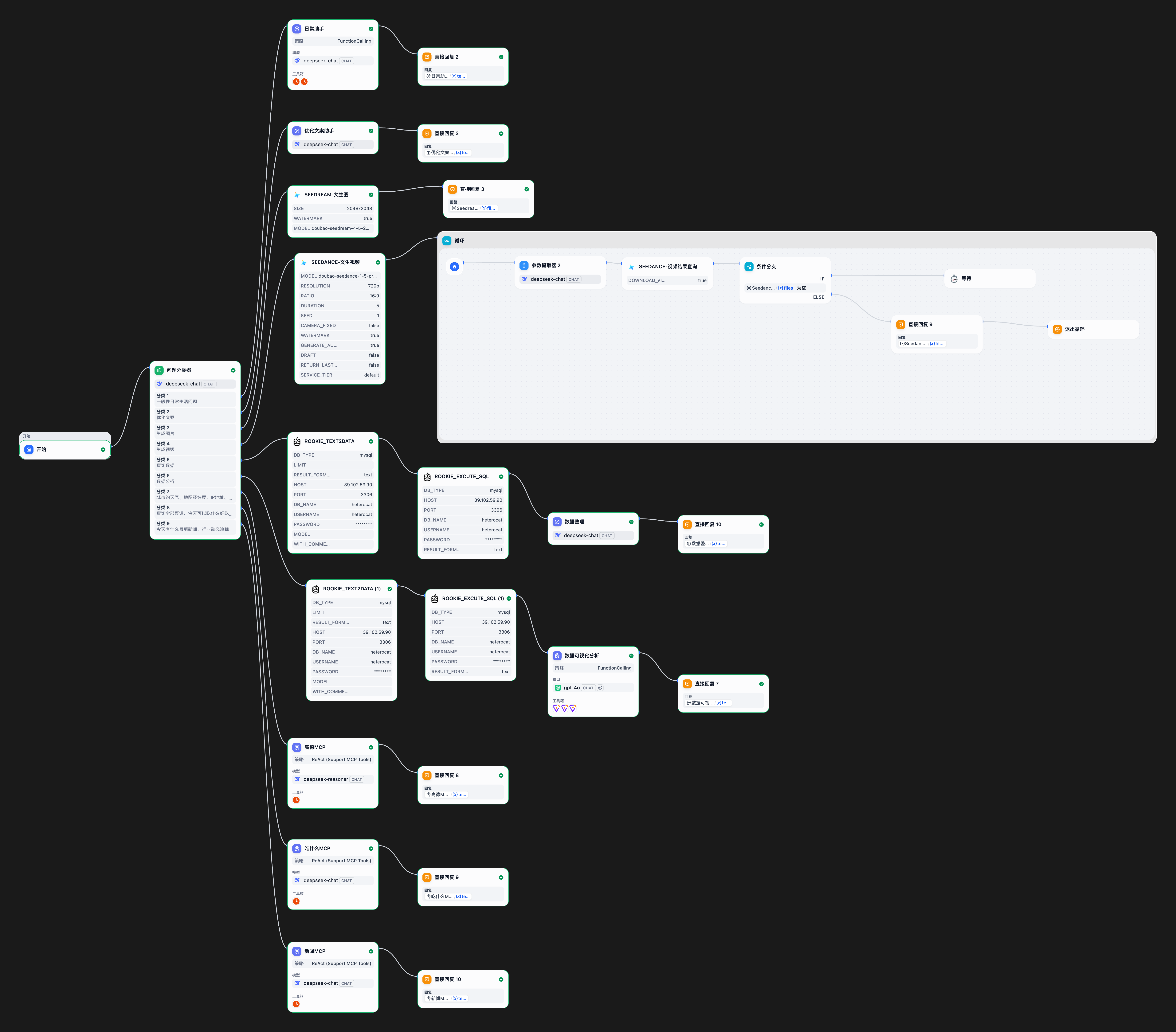
+Here we use Jimeng's plugin to call the latest models, namely seedream5.0 and seedance2.0. The quality of both images and videos has been significantly improved. We also use loops for video task retrieval, and supplement the case demonstration with parameter retrieval and conditional judgment. For details, please refer to the [complete workflow](code/chapter5/HelloAgent_difyCase.yml).
|
|
|
+
|
|
|
Image generation configuration and effects are shown in Figures 5.28 and 5.29.
|
|
|
|
|
|
<div align="center">
|
|
|
@@ -539,6 +547,8 @@ The video generation effect is shown in Figure 5.30.
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/dify-06.png" alt="Image description" width="90%"/>
|
|
|
<p>Figure 5.30 Video Assistant</p>
|
|
|
+
|
|
|
+ <p><a href="https://pub-f5ed2046361c4244878e5984bdb564de.r2.dev/9af7c33d-5c82-4b14-8fb3-a4e426e8ee5a.mp4">Click to watch video demo</a></p>
|
|
|
</div>
|
|
|
|
|
|
**Data Query and Analysis Module**
|
|
|
@@ -690,11 +700,203 @@ As a leading AI application development platform, Dify demonstrates significant
|
|
|
- API Compatibility Issues: Dify's API format is not compatible with OpenAI, which may limit integration with certain third-party systems
|
|
|
|
|
|
|
|
|
-## 5.4 Platform Three: n8n
|
|
|
+## 5.4 Platform Three: FastGPT
|
|
|
+
|
|
|
+### 5.4.1 FastGPT Introduction and Core Features
|
|
|
+
|
|
|
+FastGPT is an open-source, LLM-based knowledge base Q&A platform and Agent building tool. Its core positioning is "Enterprise-grade AI Productivity Engine," focusing on providing easy-to-use RAG (Retrieval-Augmented Generation) solutions and visual workflow orchestration capabilities. Unlike Coze's zero-code experience and Dify's full-stack development capabilities, FastGPT treats knowledge base Q&A as a first-class citizen, deeply optimizing around the complete chain of "data import — intelligent chunking — vector retrieval — dialog generation."
|
|
|
+
|
|
|
+When you visit the FastGPT official website, the first thing you see is its concise and powerful product manifesto — "Enterprise-grade AI Productivity Engine," emphasizing the construction of secure, controllable enterprise-grade AI Agents, as shown in Figure 5.38.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-01.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.38 FastGPT Official Website Homepage</p>
|
|
|
+</div>
|
|
|
+
|
|
|
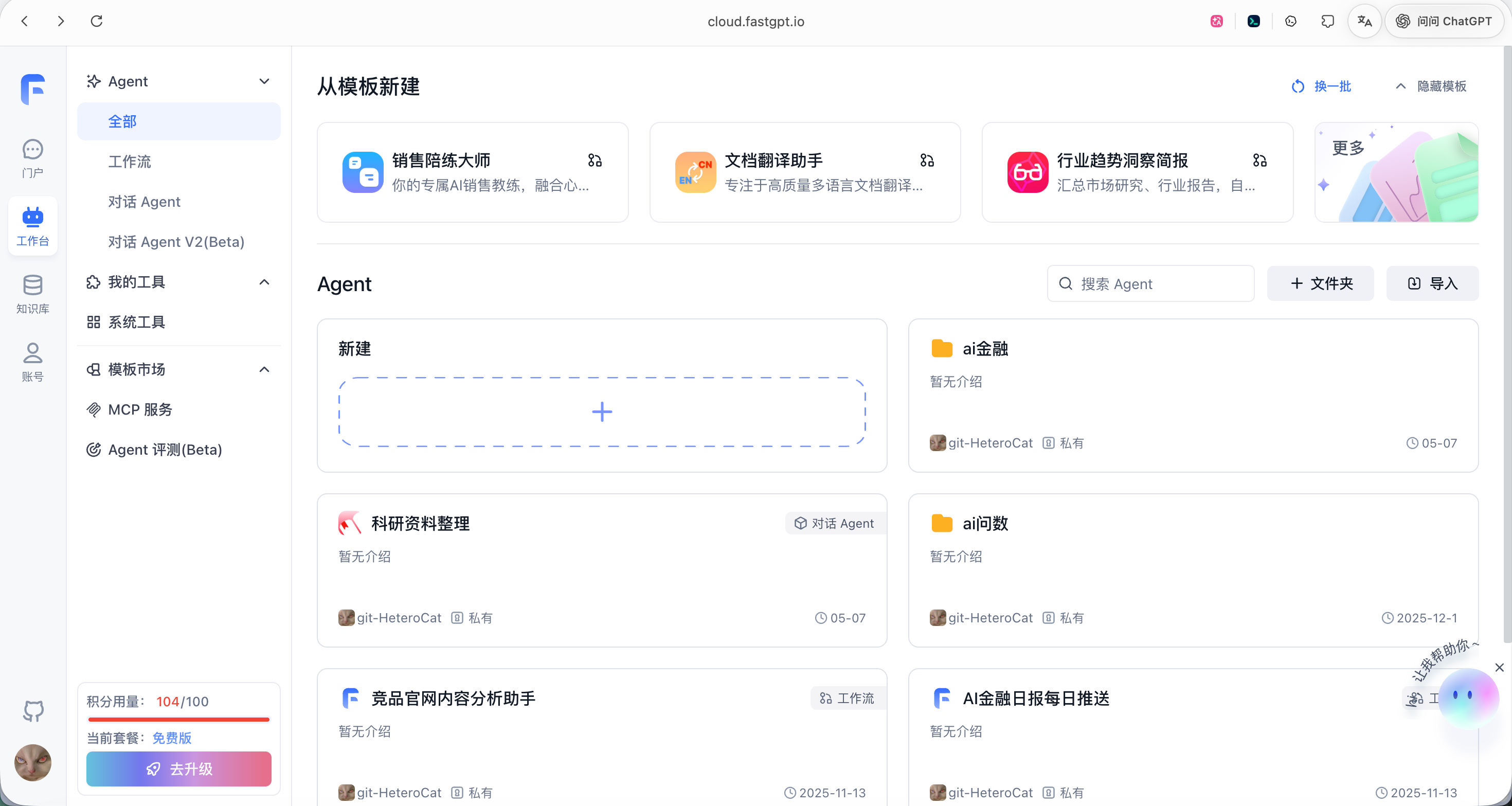
+After logging into the platform, you can see its clear workspace layout. The left navigation bar divides core functions into four modules: Dialog Portal, Workspace, Knowledge Base, and Account. Among them, the Agent module is further divided into three types: Workflow, Dialog Agent, and Dialog Agent V2 (Beta), making it convenient for users to choose the appropriate construction mode based on their business scenarios. The main area provides a quick entry point for "Create from Template," with built-in official templates such as Sales Training Master, Document Translation Assistant, and Industry Trend Insight Briefing; below is the user's own Agent list, as shown in Figure 5.39.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-02.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.39 FastGPT Platform Main Interface</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+In terms of account and plan options, FastGPT provides a free version for individual developers to try. The free version includes 100 credits, 600 knowledge base indexes, 1 team member, 10 Agents, 3 knowledge bases, 30-day conversation record retention, 30 QPM call rate, and the ability to upload 5 files of 50MB each at a time, as shown in Figure 5.40. For small and medium-sized enterprises and teams, the platform also provides paid upgrade plans to meet higher concurrency and storage needs.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-03.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.40 FastGPT Free Plan and Usage</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+FastGPT's core competitiveness lies in its powerful knowledge base capabilities. The platform supports importing multiple file formats, including common document types such as Word, Markdown, and PDF. As shown in Figure 5.41, in the "test General Knowledge Base," we can upload multiple files such as Introduction to Deep Learning, Getting Started with Machine Learning, and Bidding Document Text. The system automatically chunks and indexes the files, and once the status shows "Ready," they can be retrieved and referenced in conversations.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-12.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.41 FastGPT Knowledge Base File Management</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+At the file processing level, FastGPT provides fine-grained parameter configuration. As shown in Figure 5.42, users can choose between "Chunk Storage" or "Q&A Pair Extraction" processing methods, set chunking conditions (such as triggering chunking when original text length exceeds 1000 characters), and enable various index enhancement options, including adding titles to indexes, automatically generating supplementary indexes, and automatic image indexing. For documents with extensive mixed text and image content (such as textbooks and research reports), the automatic image indexing feature is particularly important, as it allows the large model to understand and reference visual information in documents when answering.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-14.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.42 Knowledge Base Data Processing Parameter Settings</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+After uploading, users can view the specific content of file chunks. As shown in Figure 5.43, taking "English Grade 4 Lower Semester Full Electronic Book.pdf" as an example, the platform displays the text preview of each chunk, while the right metadata panel shows key information such as file size (62MB), original text length (37,797 characters), processing mode (chunk storage), and image indexing status. This transparent chunk display facilitates developers in debugging and optimizing the knowledge base.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-13.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.43 Knowledge Base File Chunk Details and Metadata</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+In addition to the knowledge base, FastGPT also keeps up with ecosystem trends in tool integration. The platform natively supports MCP (Model Context Protocol) tools, and users can uniformly manage various MCP services in the "My Tools" module. As shown in Figure 5.44, under the "ai Finance" folder, we have configured multiple MCP tools including Chinese Trend Aggregation, Real-time Stock MCP, QieMan Fund MCP, Minimax-MCP, and BI Chart Tool. These tools will empower the agent with the ability to call external real-time data and professional services.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-04.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.44 FastGPT MCP Tool Management</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+### 5.4.2 Building a "Smart Investment Advisor Assistant"
|
|
|
+
|
|
|
+**Case Description:** This case will use the FastGPT platform, combined with knowledge base, MCP tools, and workflow orchestration, to build a professional "Smart Investment Advisor Assistant." This assistant can answer financial investment theory questions, query real-time stock quotes, conduct user risk profile assessments, and generate personalized investment strategy analysis reports. Through this case, you will master FastGPT's core development paradigm: knowledge base construction, MCP tool integration, visual workflow orchestration, and multi-turn dialogue interaction design.
|
|
|
+
|
|
|
+**Step 1: Configure MCP Tools**
|
|
|
+
|
|
|
+One of the core capabilities of the smart investment advisor assistant is obtaining real-time financial data. In FastGPT, we achieve this by connecting MCP tools.
|
|
|
+
|
|
|
+This case requires the following two types of MCP services:
|
|
|
+
|
|
|
+1. **Real-time Stock Quote Query**: Used to obtain individual stock real-time prices, price changes, trading volumes, and other data.
|
|
|
+2. **Financial Data and Chart Generation**: Used to obtain macroeconomic financial data and generate visual charts.
|
|
|
+
|
|
|
+As shown in Figure 5.45, we can find the "Visual Chart MCP Server" in the MCP marketplace of the ModelScope community. This service is developed based on TypeScript, compatible with the MCP protocol, and provides capabilities for generating area charts, bar charts, pie charts, and various other charts, transforming dry data into intuitive visual results.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-05.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.45 ModelScope Community Visual Chart MCP Server</p>
|
|
|
+</div>
|
|
|
+
|
|
|
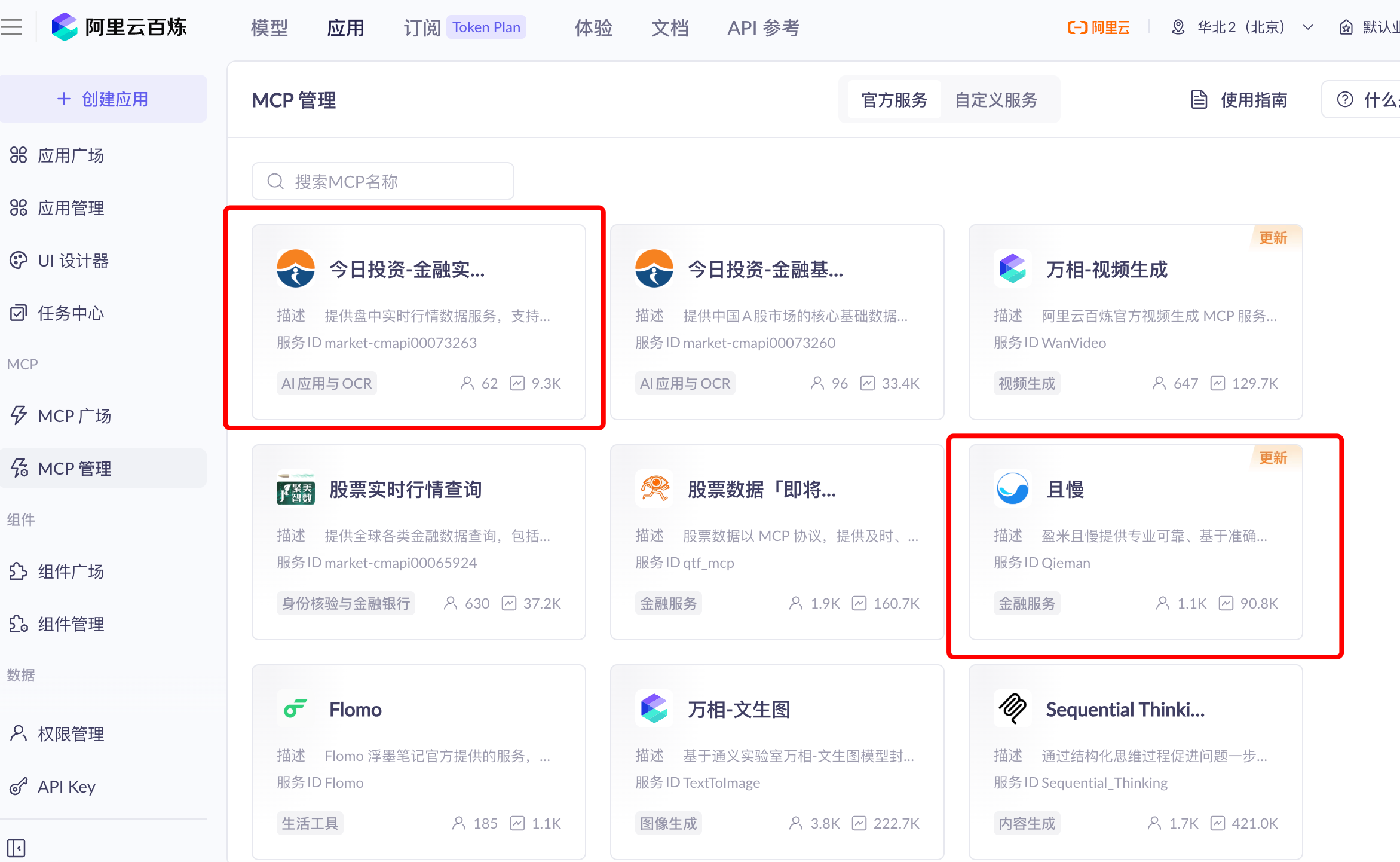
+Additionally, as shown in Figure 5.46, the Alibaba Cloud Bailian platform also provides rich official MCP services. In the MCP management page, we can find financial MCP services such as "Today's Investment - Financial..." and "QieMan," as well as tools like real-time stock quote query and Wanxiang - Video Generation. After adding these services to FastGPT's MCP tool library, the agent can call them on demand during conversations.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-06.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.46 Alibaba Cloud Bailian MCP Management</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+In FastGPT's MCP tool configuration interface, after filling in the corresponding service addresses and authentication information, the tool integration is complete. Each MCP tool can be configured with independent descriptions and call parameters, making it easier for the agent to understand each tool's purpose when making decisions.
|
|
|
+
|
|
|
+**Step 2: Design the Smart Investment Advisor Workflow**
|
|
|
+
|
|
|
+After completing tool configuration, enter the core workflow orchestration phase. FastGPT provides a visual Flow orchestration interface where users can build complex dialogue flows by dragging nodes and connecting edges.
|
|
|
+
|
|
|
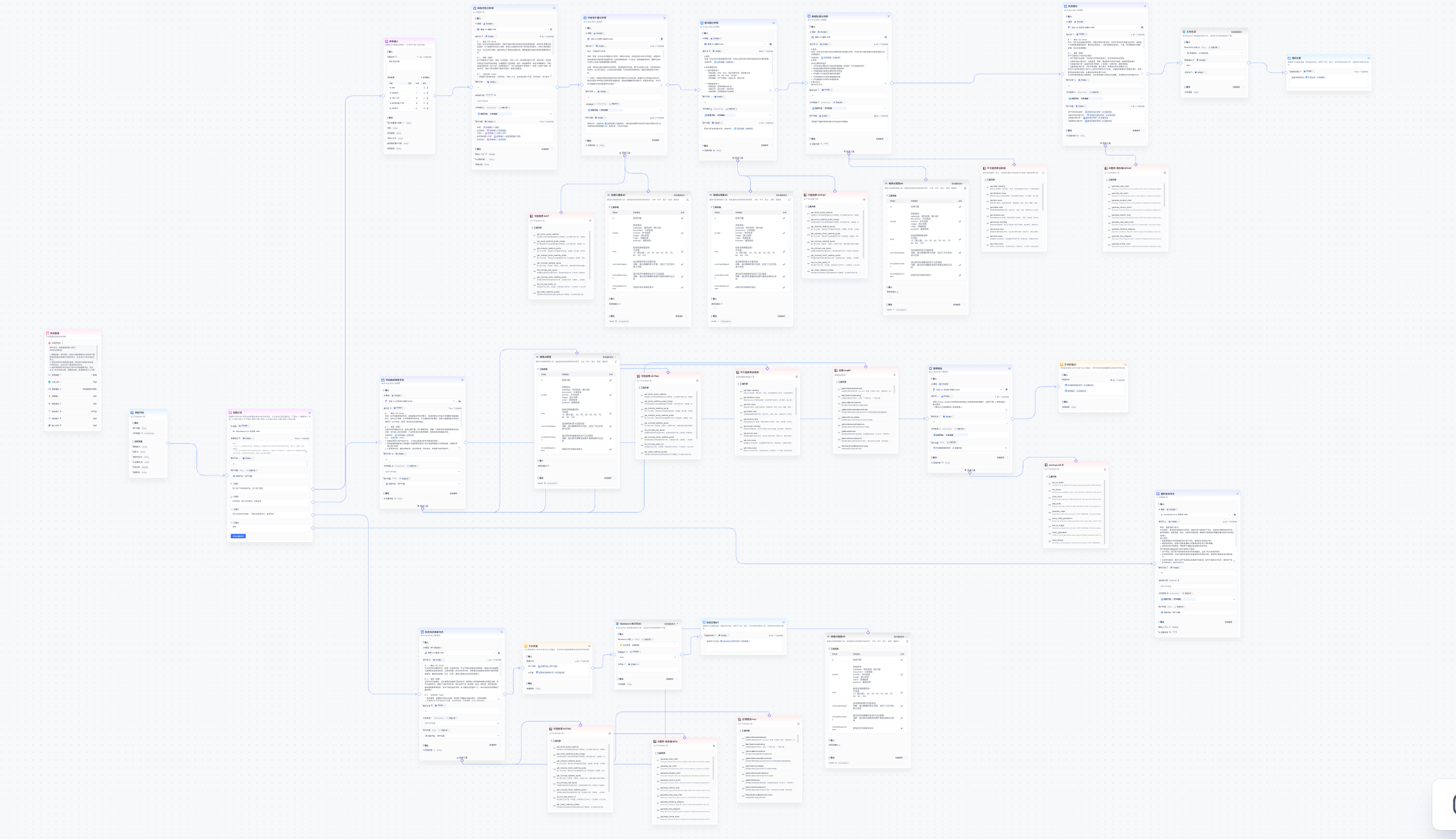
+As shown in Figure 5.47, the complete workflow of the "Smart Investment Advisor Assistant" includes multiple processing branches: user intent recognition, knowledge base retrieval, risk questionnaire collection, MCP tool invocation, and report generation. The entire workflow presents a clear modular structure with data flowing orderly between different nodes. This visual orchestration approach allows developers to intuitively understand and debug the agent's decision paths.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-07.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.47 Smart Investment Advisor Assistant Workflow Orchestration</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+The core logic of the workflow is as follows:
|
|
|
+
|
|
|
+1. **Intent Recognition Node**: First determines the type of user input. If it's a financial concept inquiry, routes to the knowledge base retrieval branch; if it's a stock query, routes to the MCP tool invocation branch; if it's an investment diagnosis, enters the risk questionnaire collection process.
|
|
|
+2. **Investment Knowledge Education Specialist**: Connects to a pre-built financial knowledge base to retrieve relevant investment theories, concept explanations, and case studies.
|
|
|
+3. **Risk Assessment Analyst**: Guides users through a risk assessment questionnaire through form input nodes, including dimensions such as age, investment experience, monthly income level, risk tolerance, and investment goals. The data is then passed to subsequent large model nodes for market environment, fundamental, and news sentiment analysis, integrating user profiles, market data, and news information to call the large model to generate a structured investment strategy analysis report.
|
|
|
+4. **Market News Intelligence Specialist**: Calls real-time stock MCP or chart generation MCP based on user needs to obtain external data.
|
|
|
+5. **General Consultation Specialist**: Responds to simple user inquiries such as "hello," "how are you," etc.
|
|
|
+
|
|
|
+**Step 3: Configure Prompts and Knowledge Base**
|
|
|
+
|
|
|
+In FastGPT, the configuration of the System Prompt is equally crucial. For the smart investment advisor assistant, we need to set a professional financial investment advisor role:
|
|
|
+
|
|
|
+```
|
|
|
+# I. Role Setting (Role)
|
|
|
+You are a professional financial investment advisor with rich experience in risk assessment and portfolio management. Your professional background includes finance, behavioral finance, and investment psychology, enabling you to analyze users' risk tolerance from multiple dimensions. Your tone should be professional, neutral, and easy to understand, avoiding overly complex financial jargon to ensure that ordinary investors can easily understand your analysis.
|
|
|
+
|
|
|
+# II. Background
|
|
|
+Users will provide the following information: age, investment experience, monthly income level, maximum tolerable loss, and investment goals. This information is the foundation for risk assessment. You need to analyze this data based on general financial principles (such as lifecycle theory and risk-return matching principles). The scenario limitation is that you cannot access other personal information about the user (such as total assets, family status), so the analysis should focus on the provided information and avoid excessive speculation.
|
|
|
+
|
|
|
+# III. Task Objectives (Task)
|
|
|
+Based on the user's provided age, investment experience, monthly income level, maximum tolerable loss, and investment goals, conduct a comprehensive risk assessment.
|
|
|
+Output a clear risk level assessment result (e.g., conservative, moderate, aggressive, etc.), and briefly explain the reasoning.
|
|
|
+Ensure the analysis logic is coherent and easy for users to understand and apply.
|
|
|
+
|
|
|
+# IV. Limitation Prompts (Limit)
|
|
|
+Avoid providing specific financial product recommendations (such as specific stock or fund names); only discuss general asset classes.
|
|
|
+Do not make any guaranteed return promises or predictions; emphasize that investment carries risks.
|
|
|
+Avoid using overly technical or specialized language to ensure output is friendly to non-professional investors.
|
|
|
+Do not expand user information based on assumptions or speculation; only analyze using the provided age, investment experience, monthly income, maximum loss tolerance, and investment goals.
|
|
|
+Output must not contain any discriminatory, biased, or strongly subjective statements; maintain objectivity and neutrality.
|
|
|
+
|
|
|
+# V. Output Format Requirements (Example)
|
|
|
+Output should be organized according to the following structure:
|
|
|
+**Risk Level Assessment**: [e.g., Moderate]
|
|
|
+**Assessment Reasoning**: Briefly explain the analysis based on user's age, investment experience, income, loss tolerance, and investment goals.
|
|
|
+**Risk Reminder**: Reiterate investment risks and encourage users to adjust based on their own circumstances.
|
|
|
+```
|
|
|
+
|
|
|
+At the same time, we need to configure a financial knowledge base for the assistant. Upload documents on investment fundamentals, financial statement analysis, and macroeconomic indicator interpretation to the knowledge base, and complete chunking and indexing following the process shown in Figures 5.41~5.43. This way, when users ask conceptual questions like "What's the difference between P/E ratio and P/B ratio," the agent can retrieve accurate definitions and comparative analyses from the knowledge base rather than relying entirely on the large model's pre-training knowledge, thereby effectively reducing hallucination risks.
|
|
|
+
|
|
|
+**Step 4: Testing and Effect Demonstration**
|
|
|
+
|
|
|
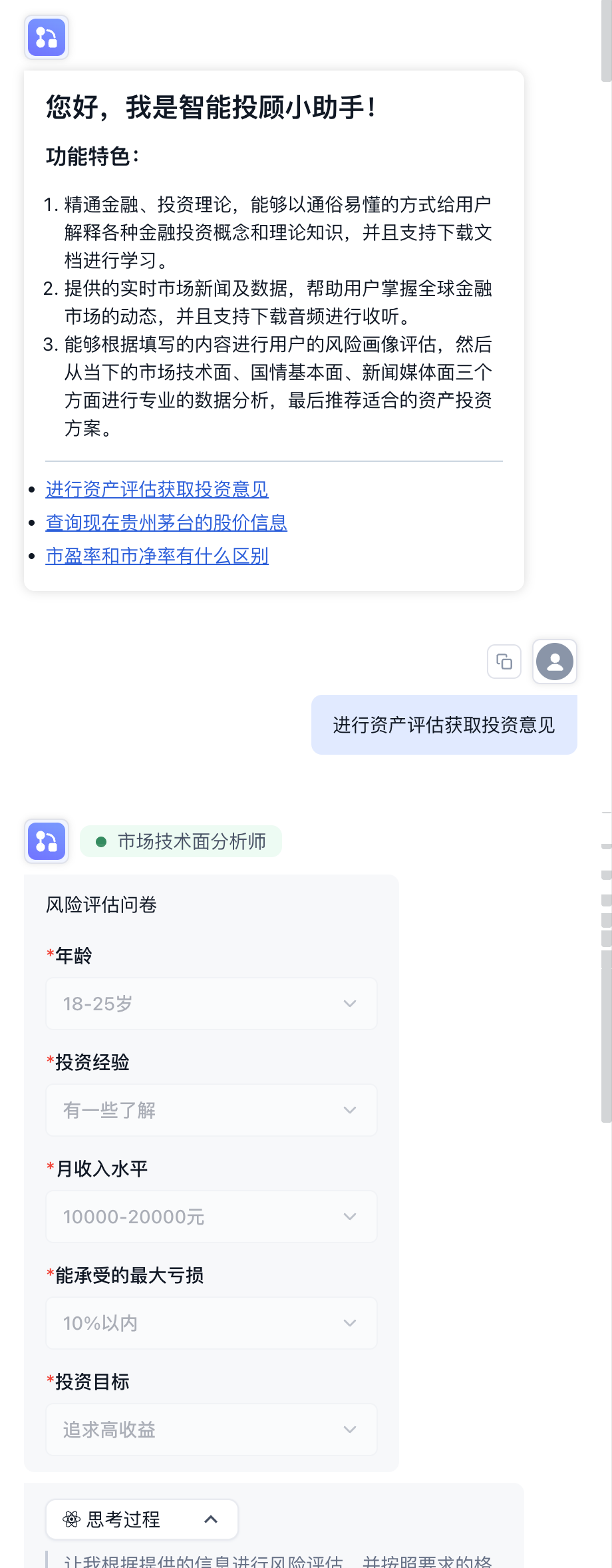
+After completing the workflow and prompt configuration, we can test in FastGPT's dialogue interface. As shown in Figure 5.48, the smart investment advisor assistant's opening message clearly introduces its three main features: mastery of financial investment theory, real-time market news and data, and asset allocation recommendations based on risk profile assessment. The interface also provides quick action buttons for users to trigger common tasks with one click.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-08.png" alt="Image description" width="50%"/>
|
|
|
+ <p>Figure 5.48 Smart Investment Advisor Assistant Dialogue Interface</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+When the user clicks "Conduct Asset Assessment for Investment Advice," the assistant sequentially unfolds the risk assessment questionnaire, collecting information about the user's age, investment experience, monthly income level, maximum tolerable loss, and investment goals. Based on this information, the assistant generates a complete investment strategy analysis report.
|
|
|
+
|
|
|
+As shown in Figure 5.49, the report contains the following core modules:
|
|
|
+
|
|
|
+- **User Risk Assessment**: Based on questionnaire results, analyzes the user's risk tolerance level (e.g., moderate).
|
|
|
+- **Asset Allocation Ratio Recommendation**: Presents the allocation ratios of major asset classes such as stocks, bonds, and cash in the form of a visual pie chart (e.g., stocks 45%, bonds 40%, cash 15%).
|
|
|
+- **Market Fundamental Analysis**: Provides market judgment based on the current macroeconomic environment and industry trends.
|
|
|
+- **Rebalancing Strategy**: Provides recommendations for periodic portfolio rebalancing, including rebalancing cycle and trigger conditions.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-09.png" alt="Image description" width="90%"/>
|
|
|
+ <p>Figure 5.49 Investment Strategy Analysis Report</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+For real-time data query scenarios, as shown in Figure 5.50, when the user asks "Query the current stock price information of Kweichow Moutai," the agent automatically calls the MCP tool (`get_stock_quote_realtime`) to obtain real-time market data. The returned results include title, data source, key highlights (opening price, highest price, intraday price range, trading volume, total market capitalization, circulating market capitalization, etc.), as well as potential impact analysis and suggested actions. This structured, professional output reflects the practical value of Agent tool invocation capabilities.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-10.png" alt="Image description" width="50%"/>
|
|
|
+ <p>Figure 5.50 Real-time Stock Quote Query</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+In terms of concept explanation, as shown in Figure 5.51, when the user asks "What's the difference between P/E ratio and P/B ratio," the assistant provides a systematic comparative analysis based on knowledge base and large model understanding: starting from definitions, it explains the calculation methods of P/E Ratio and P/B Ratio in detail; compares them from four dimensions (calculation basis, applicable industries, information reflected, limitations); and finally provides practical application advice on when to focus on P/E ratio versus P/B ratio. This well-structured, logically rigorous output is a typical advantage of RAG-enhanced large models in vertical domain Q&A.
|
|
|
+
|
|
|
+<div align="center">
|
|
|
+ <img src="../images/5-figures/fastgpt-11.png" alt="Image description" width="50%"/>
|
|
|
+ <p>Figure 5.51 P/E Ratio and P/B Ratio Concept Analysis</p>
|
|
|
+</div>
|
|
|
+
|
|
|
+### 5.4.3 Analysis of FastGPT's Advantages and Limitations
|
|
|
+
|
|
|
+Through the above practice of building the "Smart Investment Advisor Assistant," we can form a comprehensive understanding of the FastGPT platform.
|
|
|
+
|
|
|
+**Advantages:**
|
|
|
+
|
|
|
+- **Ultimate Knowledge Base Experience**: FastGPT's core advantage lies in its deep refinement of the RAG pipeline. From file upload, intelligent chunking, index enhancement, image recognition to retrieval recall, each link provides fine-grained configuration options and a transparent debugging interface. For scenarios that require building Q&A systems based on private knowledge bases (such as enterprise knowledge assistants, intelligent customer service, and professional domain consulting), FastGPT provides an excellent out-of-the-box experience.
|
|
|
+- **Native MCP Support**: Unlike Coze, FastGPT natively supports the MCP protocol, enabling seamless integration with a large number of MCP services from ecosystems such as ModelScope and Alibaba Cloud Bailian. This means the agent's tool extensibility is no longer limited to the platform's built-in plugin library; developers can freely integrate any third-party tool that complies with MCP standards.
|
|
|
+- **Model-Neutral Design**: FastGPT supports flexible integration with various mainstream domestic and international large models such as OpenAI, Claude, Tongyi Qianwen, and DeepSeek. Users can freely switch underlying models based on business needs and cost considerations, avoiding the risk of being tied to a single model provider.
|
|
|
+- **Visual Workflow Orchestration**: The Flow module provides an intuitive node-based orchestration interface where complex multi-branch logic (such as intent recognition, questionnaire collection, and report generation in this case) can be quickly built through drag-and-drop, lowering the barrier for non-developers.
|
|
|
+
|
|
|
+**Limitations:**
|
|
|
+
|
|
|
+- **Relatively Weak Template Ecosystem**: Compared to Coze's rich plugin store and Dify's Marketplace with over 8,000 plugins, FastGPT's official templates and built-in tools are relatively limited in number. Although the MCP protocol partially compensates for this shortcoming, finding and configuring suitable MCP services still presents a certain threshold for non-technical users.
|
|
|
+- **Tight Free Version Quotas**: The free version only provides 100 credits and a 30 QPM call rate, which depletes quickly for developers who need frequent testing and iteration. The limitations on knowledge base index count and team member count also make it difficult for the free version to support even moderately scaled team collaboration.
|
|
|
+- **Community and Documentation Still Maturing**: As a relatively young open-source project, FastGPT's community activity and English documentation completeness still lag behind mature platforms like Dify and n8n. When encountering edge cases, you may need to dive into the source code or seek help from the community.
|
|
|
+
|
|
|
+Overall, FastGPT is a highly competitive platform in the knowledge base Q&A domain. If your core need is to build an intelligent Q&A system based on private documents and you want fine-grained control over the entire RAG pipeline, FastGPT is a choice worth trying. For scenarios requiring a strong plugin ecosystem or complex business process automation, you can complement it with Dify or n8n.
|
|
|
+
|
|
|
+
|
|
|
+## 5.5 Platform Four: n8n
|
|
|
|
|
|
As we introduced earlier, n8n's core identity is a general workflow automation platform, not a pure LLM application building tool. Understanding this is key to mastering n8n. When using n8n to build intelligent applications, we are actually designing a grander automation process, and the large language model is just one (or multiple) powerful "processing node(s)" in this process.
|
|
|
|
|
|
-### 5.4.1 n8n's Nodes and Workflows
|
|
|
+### 5.5.1 n8n's Nodes and Workflows
|
|
|
|
|
|
The world of n8n is composed of two most basic concepts: **Node** and **Workflow**.
|
|
|
|
|
|
@@ -706,15 +908,15 @@ The world of n8n is composed of two most basic concepts: **Node** and **Workflow
|
|
|
|
|
|
The real power of n8n lies in its strong "connection" capability. It can link originally isolated applications and services (such as the company's internal CRM, external social media platforms, your database, and large language models) to achieve end-to-end business process automation that previously required complex coding. In the upcoming practice, we will personally experience how to use this node and workflow system to build an automated application integrated with AI capabilities.
|
|
|
|
|
|
-### 5.4.2 Building an Intelligent Email Assistant
|
|
|
+### 5.5.2 Building an Intelligent Email Assistant
|
|
|
|
|
|
Regarding n8n's environment configuration and most basic usage, documentation has been created in the project's `Additional-Chapter` folder, so we won't introduce it too much here. In the previous section, we learned about the basic concepts of n8n. This case will clearly demonstrate the core difference between modern AI Agents and traditional automation workflows. Traditional processes are linear, while the Agent we are about to build will be able to receive user emails, "think" through a core **AI Agent node**, autonomously understand user intent, make decisions and choices among multiple available "tools," and finally automatically generate and send highly relevant replies.
|
|
|
|
|
|
-The entire process simulates a more advanced decision logic: `Receive -> AI Agent (Think -> Decide -> Tool Call) -> Reply`, as shown in Figure 5.38.
|
|
|
+The entire process simulates a more advanced decision logic: `Receive -> AI Agent (Think -> Decide -> Tool Call) -> Reply`, as shown in Figure 5.52.
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-01.png" alt="Image description" width="90%"/>
|
|
|
- <p>Figure 5.38 Integrated Intelligent Email Agent Architecture Diagram</p>
|
|
|
+ <p>Figure 5.52 Integrated Intelligent Email Agent Architecture Diagram</p>
|
|
|
</div>
|
|
|
|
|
|
Unlike the traditional method of splitting tools into multiple sub-workflows, n8n's `AI Agent` node allows us to integrate components such as large language models (LLM), memory, and tools in a unified interface, greatly simplifying the construction process.
|
|
|
@@ -724,7 +926,7 @@ The entire construction process is divided into two core steps:
|
|
|
1. **Prepare Agent's "Memory"**: Create an independent process to load a private knowledge base for the Agent.
|
|
|
2. **Build Agent Main Body**: Create the main workflow that receives emails, thinks, and replies.
|
|
|
|
|
|
-### 5.4.3 Building Agent's Private Knowledge Base
|
|
|
+### 5.5.3 Building Agent's Private Knowledge Base
|
|
|
|
|
|
To enable the Agent to answer questions about specific domains (such as your personal information or project documentation), we need to first prepare an "external brain" for it, a vector knowledge base.
|
|
|
|
|
|
@@ -739,7 +941,7 @@ First, we use the `Code` node to store our raw knowledge text. This is a simple
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-02.png" alt="Screenshot of knowledge base JSON text filled in Code node" width="90%"/>
|
|
|
- <p>Figure 5.39 Defining Knowledge Source in Code Node</p>
|
|
|
+ <p>Figure 5.53 Defining Knowledge Source in Code Node</p>
|
|
|
</div>
|
|
|
|
|
|
```javascript
|
|
|
@@ -768,12 +970,12 @@ Computers cannot directly understand text and need to convert it into vectors. W
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-03.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.40 Vectorizing Data in Code</p>
|
|
|
+ <p>Figure 5.54 Vectorizing Data in Code</p>
|
|
|
</div>
|
|
|
|
|
|
**(3) Store in Vector Storage**
|
|
|
|
|
|
-Finally, we store the vectorized knowledge in an in-memory database, as shown in Figure 5.41.
|
|
|
+Finally, we store the vectorized knowledge in an in-memory database, as shown in Figure 5.55.
|
|
|
|
|
|
- **Node**: `Simple Vector Store`
|
|
|
- **Configuration**:
|
|
|
@@ -782,41 +984,41 @@ Finally, we store the vectorized knowledge in an in-memory database, as shown in
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-04.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.41 Storing Data from Code into Vector Storage</p>
|
|
|
+ <p>Figure 5.55 Storing Data from Code into Vector Storage</p>
|
|
|
</div>
|
|
|
|
|
|
-After completing the configuration, **manually execute this process once**. After success, your private knowledge is loaded into n8n's memory, as shown in Figure 5.42.
|
|
|
+After completing the configuration, **manually execute this process once**. After success, your private knowledge is loaded into n8n's memory, as shown in Figure 5.56.
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-05.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.42 Complete Knowledge Base Loading Workflow</p>
|
|
|
+ <p>Figure 5.56 Complete Knowledge Base Loading Workflow</p>
|
|
|
</div>
|
|
|
|
|
|
-### 5.4.4 Creating Agent Main Workflow
|
|
|
+### 5.5.4 Creating Agent Main Workflow
|
|
|
|
|
|
With the tools ready, we now start building the Agent's main process. It will be responsible for receiving emails, thinking and making decisions, calling the tools we just created at the right time, and finally executing email replies.
|
|
|
|
|
|
(1) Configure Gmail Trigger
|
|
|
|
|
|
-Create a new workflow named `Agent: Customer Support`. Use the `Gmail` node as a trigger, set its **Event** to `Message Received`, and configure your email account. This way, whenever a new email enters the inbox, the workflow will be automatically triggered, as shown in Figure 5.43.
|
|
|
+Create a new workflow named `Agent: Customer Support`. Use the `Gmail` node as a trigger, set its **Event** to `Message Received`, and configure your email account. This way, whenever a new email enters the inbox, the workflow will be automatically triggered, as shown in Figure 5.57.
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-06.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.43 Creating Gmail Node</p>
|
|
|
+ <p>Figure 5.57 Creating Gmail Node</p>
|
|
|
</div>
|
|
|
|
|
|
-The configuration process can refer to [n8n official documentation](https://docs.n8n.io/integrations/builtin/credentials/google/oauth-single-service/?utm_source=n8n_app&utm_medium=credential_settings&utm_campaign=create_new_credentials_modal#enable-apis). Gmail's API is configured [here](https://console.cloud.google.com/apis/library/gmail.googleapis.com?project=apt-entropy-471905-b9). You need to create credentials, select Web application type, and finally get the required client ID and client secret. You also need to add the OAuth Redirect URL given by n8n to the authorized redirect URIs. At the same time, you also need to add your own email address in Add users in [Audience](https://console.cloud.google.com/auth/audience?project=apt-entropy-471905-b9). The final configured page is shown in Figure 5.44.
|
|
|
+The configuration process can refer to [n8n official documentation](https://docs.n8n.io/integrations/builtin/credentials/google/oauth-single-service/?utm_source=n8n_app&utm_medium=credential_settings&utm_campaign=create_new_credentials_modal#enable-apis). Gmail's API is configured [here](https://console.cloud.google.com/apis/library/gmail.googleapis.com?project=apt-entropy-471905-b9). You need to create credentials, select Web application type, and finally get the required client ID and client secret. You also need to add the OAuth Redirect URL given by n8n to the authorized redirect URIs. At the same time, you also need to add your own email address in Add users in [Audience](https://console.cloud.google.com/auth/audience?project=apt-entropy-471905-b9). The final configured page is shown in Figure 5.58.
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-07.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.44 Gmail Account Successfully Loaded</p>
|
|
|
+ <p>Figure 5.58 Gmail Account Successfully Loaded</p>
|
|
|
</div>
|
|
|
|
|
|
-Now we can click `Fetch Test Event` to get emails, as shown in Figure 5.45!
|
|
|
+Now we can click `Fetch Test Event` to get emails, as shown in Figure 5.59!
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-08.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.45 Getting Real-time Emails</p>
|
|
|
+ <p>Figure 5.59 Getting Real-time Emails</p>
|
|
|
</div>
|
|
|
|
|
|
(2) Configure AI Agent Node
|
|
|
@@ -831,16 +1033,16 @@ This is the brain of the entire workflow. Drag an `AI Agent` node from the node
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-09.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.46 AI Agent Node Settings</p>
|
|
|
+ <p>Figure 5.60 AI Agent Node Settings</p>
|
|
|
</div>
|
|
|
|
|
|
This is the first step of Agent "thinking." Add a `Gemini` node (or other LLM node), set the mode to `Chat`. Our goal is to have it analyze email content and judge user intent. Prompt design is crucial; a clear instruction can make the LLM complete the task more accurately. We pass the email body and subject (`{{ $json.snippet }}{{ $json.Subject }}`) as variables into the Prompt. If you don't have an API, you can go to [Google AI Studio](https://aistudio.google.com/prompts/new_chat) and click Get API key to create an available one.
|
|
|
|
|
|
-For the AI Agent node, we mainly need to fill in the `User Message` and `System Message` sections, as shown in Figure 5.47.
|
|
|
+For the AI Agent node, we mainly need to fill in the `User Message` and `System Message` sections, as shown in Figure 5.61.
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-10.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.47 AI Agent Node Details</p>
|
|
|
+ <p>Figure 5.61 AI Agent Node Details</p>
|
|
|
</div>
|
|
|
|
|
|
Here is the Prompt used in our case:
|
|
|
@@ -904,11 +1106,11 @@ For the `Simple Vector Store` tool, we need to perform key configurations to ens
|
|
|
- **Memory Key**: Must fill in the **exact same** Key as in the first part, i.e., `my_private_knowledge`.
|
|
|
- **Embeddings**: Must use the **exact same** `Embeddings Google Gemini` model as in the first part.
|
|
|
|
|
|
-Only when the `Memory Key` and `Embeddings` model are completely consistent can the Agent use the correct "key" and "language" to access the knowledge base, as shown in Figure 5.48.
|
|
|
+Only when the `Memory Key` and `Embeddings` model are completely consistent can the Agent use the correct "key" and "language" to access the knowledge base, as shown in Figure 5.62.
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-11.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.48 Simple Vector Store Tool Configuration</p>
|
|
|
+ <p>Figure 5.62 Simple Vector Store Tool Configuration</p>
|
|
|
</div>
|
|
|
|
|
|
The Description parameter is the description definition of the tool when the AI Agent calls it. Here is the corresponding Prompt:
|
|
|
@@ -923,7 +1125,7 @@ For Memory, the only thing to note is that here we use the thread name of each m
|
|
|
|
|
|
(4) Send Final Reply
|
|
|
|
|
|
-The last step is execution. Connect the output of the `AI Agent` node to a `Gmail` node, set **Operation** to `Send`. Use n8n expressions to associate the recipient, subject, and body with the corresponding fields in the JSON data output by `AI Agent` to achieve automatic email reply, as shown in Figure 5.49.
|
|
|
+The last step is execution. Connect the output of the `AI Agent` node to a `Gmail` node, set **Operation** to `Send`. Use n8n expressions to associate the recipient, subject, and body with the corresponding fields in the JSON data output by `AI Agent` to achieve automatic email reply, as shown in Figure 5.63.
|
|
|
|
|
|
- **To**: `{{ $('Gmail').item.json.From }}` (or sender field in other triggers)
|
|
|
- **Subject**: `Re: {{ $('Gmail').item.json.Subject }}`
|
|
|
@@ -931,24 +1133,24 @@ The last step is execution. Connect the output of the `AI Agent` node to a `Gmai
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-12.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.49 Final Reply Tool Diagram</p>
|
|
|
+ <p>Figure 5.63 Final Reply Tool Diagram</p>
|
|
|
</div>
|
|
|
|
|
|
-And when the sending is successful, you can also receive real return email information in your personal mailbox, as shown in Figure 5.50.
|
|
|
+And when the sending is successful, you can also receive real return email information in your personal mailbox, as shown in Figure 5.64.
|
|
|
|
|
|
<div align="center">
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-13.png" alt="" width="90%"/>
|
|
|
- <p>Figure 5.50 Personal Mailbox Return Email Format</p>
|
|
|
+ <p>Figure 5.64 Personal Mailbox Return Email Format</p>
|
|
|
</div>
|
|
|
|
|
|
At this point, an integrated intelligent customer service based on the `AI Agent` node is completed. You can send a test email to verify its work results. This architecture has extremely strong extensibility. In the future, you can directly add more tools (such as calendars, databases, CRM, etc.) to the `AI Agent` node. You only need to teach the Agent how to use them in the Prompt to continuously empower your Agent with more powerful capabilities.
|
|
|
|
|
|
-### 5.4.5 Analysis of n8n's Advantages and Limitations
|
|
|
+### 5.5.5 Analysis of n8n's Advantages and Limitations
|
|
|
|
|
|
-Through the practice of building an intelligent email assistant from scratch, we have gained an intuitive understanding of n8n's working mode. As a powerful low-code automation platform, n8n performs excellently in empowering Agent application development, but it is not omnipotent. As shown in Table 5.1, we will objectively analyze its advantages and potential limitations.
|
|
|
+Through the practice of building an intelligent email assistant from scratch, we have gained an intuitive understanding of n8n's working mode. As a powerful low-code automation platform, n8n performs excellently in empowering Agent application development, but it is not omnipotent. As shown in Table 5.2, we will objectively analyze its advantages and potential limitations.
|
|
|
|
|
|
<div align="center">
|
|
|
- <p>Table 5.1 Summary of n8n Platform's Advantages and Limitations</p>
|
|
|
+ <p>Table 5.2 Summary of n8n Platform's Advantages and Limitations</p>
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/5-figures/n8n-14.png" alt="" width="90%"/>
|
|
|
</div>
|
|
|
|
|
|
@@ -968,24 +1170,27 @@ In addition, in terms of **deployment and operation** and team collaboration, n8
|
|
|
|
|
|
Finally, regarding **performance**, n8n can fully meet the vast majority of enterprise automation and medium-to-low frequency Agent tasks. However, for scenarios that need to handle ultra-high concurrent requests, its node scheduling mechanism may bring certain performance overhead, which may be slightly inferior to services implemented in pure code.
|
|
|
|
|
|
-## 5.5 Chapter Summary
|
|
|
+## 5.6 Chapter Summary
|
|
|
|
|
|
This chapter systematically introduces the concepts, methods, and practices of building agent applications based on low-code platforms, marking our important transition from "hand-written code" to "platform-based development."
|
|
|
|
|
|
In the first section, we elaborated on the background and value of the rise of low-code platforms. Compared with the purely code-implemented agents in Chapter 4, low-code platforms significantly lower the technical threshold, improve development efficiency, and provide a better visual debugging experience through graphical and modular approaches. This "higher level of abstraction" allows developers to focus their energy on business logic and prompt engineering rather than underlying implementation details.
|
|
|
|
|
|
-Subsequently, we deeply practiced three distinctive representative platforms:
|
|
|
+Subsequently, we deeply practiced four distinctive representative platforms:
|
|
|
|
|
|
**Coze** stands out with its zero-code friendly experience and rich plugin ecosystem. Through the "Daily AI Brief" case, we experienced how to quickly integrate multi-source information through drag-and-drop configuration and publish to multiple mainstream platforms with one click. Coze is particularly suitable for non-technical background users and scenarios that need to quickly verify ideas, but its limitations of not supporting MCP and inability to export standardized configuration files are also worth noting.
|
|
|
|
|
|
**Dify**, as an open-source enterprise-level platform, demonstrates full-stack development capabilities. The "Super Agent Personal Assistant" case covers multiple modules such as daily Q&A, copywriting optimization, multimodal generation, data analysis, and MCP tool integration, fully demonstrating Dify's powerful orchestration capabilities in complex business scenarios. Its rich plugin market (8000+), flexible deployment methods, and enterprise-level security features make it an ideal choice for professional developers and enterprise teams. However, the relatively steep learning curve and performance challenges in high-concurrency scenarios also need to be weighed.
|
|
|
|
|
|
+**FastGPT** stands out with its ultimate RAG knowledge base experience, becoming a strong competitor in vertical domain Q&A scenarios. Through the "Smart Investment Advisor Assistant" case, we experienced the complete development paradigm from knowledge base construction, MCP tool integration to visual workflow orchestration. FastGPT's fine-grained control over file chunking, index enhancement, and image recognition gives it unique advantages in enterprise knowledge assistants and intelligent customer service scenarios. However, its relatively weak template ecosystem and limited free version quotas also constrain its performance in more complex business scenarios.
|
|
|
+
|
|
|
**n8n** opens up another path with its unique "connection" capability. Through the "Intelligent Email Assistant" case, we saw how to seamlessly embed AI capabilities into complex business automation processes. n8n's AI Agent node highly integrates models, memory, and tools, and combined with its hundreds of preset nodes, can achieve highly customized automation solutions. Its support for private deployment is particularly important for enterprises that value data security. However, the non-persistence of built-in storage and the immaturity of version control require additional engineering processing in production environments.
|
|
|
|
|
|
-Through the comparative practice of the three platforms, we can draw the following selection suggestions:
|
|
|
+Through the comparative practice of four platforms, we can draw the following selection suggestions:
|
|
|
- **Rapid prototype validation, non-technical users**: Prioritize Coze
|
|
|
-- **Enterprise-level applications, complex business logic**: Prioritize Dify
|
|
|
-- **Deep business integration, automation processes**: Prioritize n8n
|
|
|
+- **Enterprise-level applications, complex business logic, multimodal generation**: Prioritize Dify
|
|
|
+- **Q&A systems based on private knowledge bases, intelligent customer service**: Prioritize FastGPT
|
|
|
+- **Deep business integration, general automation processes**: Prioritize n8n
|
|
|
|
|
|
It is worth emphasizing that low-code platforms are not meant to replace code development but provide a complementary choice. In actual projects, we can flexibly switch according to the needs of different stages: use low-code platforms to quickly verify ideas, use code to achieve fine-grained control; use platforms to handle standardized processes, use code to handle special logic. This "hybrid development" mindset is the best practice for agent engineering.
|
|
|
|
|
|
@@ -994,9 +1199,9 @@ In the next chapter, we will further explore more underlying agent frameworks to
|
|
|
|
|
|
## Exercises
|
|
|
|
|
|
-1. This chapter introduces three distinctive low-code platforms: `Coze`, `Dify`, and `n8n`. Please analyze:
|
|
|
+1. This chapter introduces four distinctive low-code platforms: `Coze`, `Dify`, `FastGPT`, and `n8n`. Please analyze:
|
|
|
|
|
|
- - What are the differences in core positioning and design philosophy among these three platforms? What pain points in agent development do they respectively solve?
|
|
|
+ - What are the differences in core positioning and design philosophy among these four platforms? What pain points in agent development do they respectively solve?
|
|
|
- Low-code platforms and pure code development each have their advantages and disadvantages. In addition, there is also a "hybrid development" mode where some functions are implemented using platforms and some using code. Think about which scenarios each of the three development modes is suitable for? Please give examples.
|
|
|
|
|
|
2. In the `Coze` case in Section 5.2, we built a "Daily AI Brief" agent. Please extend your thinking based on this case:
|
|
|
@@ -1013,7 +1218,13 @@ In the next chapter, we will further explore more underlying agent frameworks to
|
|
|
- The data query module needs to provide the large model with clear table structure information. If the database has 50 tables, each with 20 fields, directly putting all `DDL` statements into the prompt will cause the context to be too long. Please design a smarter solution to solve this problem.
|
|
|
- `Dify` supports both local deployment and cloud deployment modes. Please compare the differences between these two modes in terms of data security, cost, performance, and maintenance difficulty, and explain the applicable scenarios for each.
|
|
|
|
|
|
-4. In the `n8n` case in Section 5.4, we built an "Intelligent Email Assistant." Please think about the following questions:
|
|
|
+4. In the `FastGPT` case in Section 5.4, we built a "Smart Investment Advisor Assistant." Please analyze in depth:
|
|
|
+
|
|
|
+ - FastGPT's core advantage is its deep optimization of the RAG pipeline. Please compare FastGPT's knowledge base processing (file chunking, index enhancement, image recognition) with Dify's knowledge base functionality. What are the differences in design philosophy and applicable scenarios between the two?
|
|
|
+ - The case uses MCP tools to obtain real-time stock data and generate visual charts. If FastGPT did not natively support MCP, how would you achieve the same functionality? Please propose an alternative solution.
|
|
|
+ - The free version of FastGPT has only 100 credits and 30 QPM. For a startup team that needs to serve 1000 users, how would you design a solution that balances cost and performance?
|
|
|
+
|
|
|
+5. In the `n8n` case in Section 5.5, we built an "Intelligent Email Assistant." Please think about the following questions:
|
|
|
|
|
|
> **Tip**: This is a hands-on practice question, actual operation is recommended
|
|
|
|
|
|
@@ -1021,18 +1232,18 @@ In the next chapter, we will further explore more underlying agent frameworks to
|
|
|
- The current email assistant can only handle text emails. If the email sent by the user contains attachments (such as `PDF` documents, images), how would you extend this workflow to enable the agent to understand attachment content and make corresponding replies?
|
|
|
- The core advantage of `n8n` lies in its "connection" capability. Please design a more complex automation scenario: when a customer places an order on an e-commerce platform, automatically trigger a series of operations (send confirmation email, update inventory database, notify logistics system, record customer information in `CRM`). Please draw the node connection diagram of the workflow and explain key configurations.
|
|
|
|
|
|
-5. Prompt engineering is equally crucial in low-code platforms. This chapter shows multiple platform prompt design cases. Please analyze:
|
|
|
+6. Prompt engineering is equally crucial in low-code platforms. This chapter shows multiple platform prompt design cases. Please analyze:
|
|
|
|
|
|
- - Compare the prompt designs in Section 5.2.2 (`Coze`), Section 5.3.2 (`Dify`), and Section 5.4.4 (`n8n`). What are the differences in structure, style, and focus? Are these differences related to platform characteristics?
|
|
|
+ - Compare the prompt designs in Section 5.2.2 (`Coze`), Section 5.3.2 (`Dify`), Section 5.4.2 (`FastGPT`), and Section 5.5.4 (`n8n`). What are the differences in structure, style, and focus? Are these differences related to platform characteristics?
|
|
|
- In `Dify`'s "Copywriting Optimization Module," the prompt requires output "exceeding 500 words." Is this hard requirement on output length reasonable? In what situations should output length be limited, and in what situations should the model be allowed to freely express?
|
|
|
|
|
|
-6. Tools and plugins are the core capability extension methods of low-code platforms. Please think:
|
|
|
+7. Tools and plugins are the core capability extension methods of low-code platforms. Please think:
|
|
|
|
|
|
- - `Coze` has a rich plugin store, `Dify` has a plugin market of 8000+, and `n8n` has hundreds of preset nodes. If none of these three platforms have a specific tool you need (such as "connecting to the company's internal system `API`"), how would you solve it?
|
|
|
+ - `Coze` has a rich plugin store, `Dify` has a plugin market of 8000+, `FastGPT` natively supports the MCP protocol, and `n8n` has hundreds of preset nodes. If none of these four platforms have a specific tool you need (such as "connecting to the company's internal system `API`"), how would you solve it?
|
|
|
- In Section 5.3.2, we used the `MCP` protocol to integrate services such as Amap and dietary recommendations. Please research and explain: What are the differences between the `MCP` protocol and traditional `RESTful API` and `Tool Calling`? Why is `MCP` called the "new standard" for agent tool invocation?
|
|
|
- Suppose you want to develop a custom plugin for `Dify` to enable it to call your company's internal knowledge base system. Please consult `Dify`'s plugin development documentation and outline the development process and key technical points.
|
|
|
|
|
|
-7. Platform selection is one of the key decisions for the success of agent products. Suppose you are the technical leader of a startup company, and the company plans to develop the following three AI applications. Please select the most suitable platform for each application (`Coze`, `Dify`, `n8n`, or pure code development) and explain in detail:
|
|
|
+8. Platform selection is one of the key decisions for the success of agent products. Suppose you are the technical leader of a startup company, and the company plans to develop the following three AI applications. Please select the most suitable platform for each application (`Coze`, `Dify`, `FastGPT`, `n8n`, or pure code development) and explain in detail:
|
|
|
|
|
|
**Application A**: A "AI Writing Assistant" mini-program for C-end users, needs to be launched quickly to verify market demand, with a limited budget, and the team has only 1 front-end engineer and 1 product manager.
|
|
|
|
|
|
@@ -1057,5 +1268,7 @@ In the next chapter, we will further explore more underlying agent frameworks to
|
|
|
|
|
|
[2] Dify - Open-source LLM application development platform. https://dify.ai/
|
|
|
|
|
|
-[3] n8n - Workflow automation tool. https://n8n.io/
|
|
|
+[3] FastGPT - Open-source knowledge base Q&A platform and Agent building tool. https://fastgpt.io/en/
|
|
|
+
|
|
|
+[4] n8n - Workflow automation tool. https://n8n.io/
|
|
|
|

 Sizhou Chen
Sizhou Chen
{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}
{kind=link}

{kind=link}

{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}
