|
|
@@ -57,13 +57,13 @@
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-2.png" alt="图片描述" width="90%"/>
|
|
|
</div>
|
|
|
|
|
|
-这种差异使得LLM智能体可以直接处理高层级、模糊且充满上下文信息的自然语言指令。它不需要用户将需求拆解成机器可以理解的结构化输入,只需要输入人类的自然语言即可。
|
|
|
+这种差异使得LLM智能体可以直接处理高层级、模糊且充满上下文信息的自然语言指令。让我们以一个“智能旅行助手”为例来说明。
|
|
|
|
|
|
-以“策划一场团队研讨会”为例,LLM智能体的一种工作方式是:
|
|
|
+在LLM智能体出现之前,规划旅行通常意味着用户需要在多个专用应用(如天气、地图、预订网站)之间手动切换,并由用户自己扮演信息整合与决策的角色。而一个LLM智能体则能将这个流程整合起来。当接收到“规划一次厦门之旅”这样的模糊指令时,它的工作方式体现了以下几点:
|
|
|
|
|
|
-1. <strong>分解与规划</strong>:将大目标拆解成多个小步骤(如确认预算、搜索场地、设计议程)。
|
|
|
-2. <strong>使用工具</strong>:调用搜索引擎、预订网站等外部API来获取实时信息。
|
|
|
-3. <strong>记忆与修正</strong>:记住用户的反馈(如“场地太贵了”)并根据新情况调整计划。
|
|
|
+- <strong>规划与推理</strong>:智能体首先会将这个高层级目标分解为一系列逻辑子任务,例如:`[确认出行偏好] -> [查询目的地信息] -> [制定行程草案] -> [预订票务住宿]`。这是一个内在的、由模型驱动的规划过程。
|
|
|
+- <strong>工具使用</strong>:在执行规划时,智能体识别到信息缺口,会主动调用外部工具来补全。例如,它会调用天气查询接口获取实时天气,并基于“预报有雨”这一信息,在后续规划中倾向于推荐室内活动。
|
|
|
+- <strong>动态修正</strong>:在交互过程中,智能体会将用户的反馈(如“这家酒店超出预算”)视为新的约束,并据此调整后续的行动,重新搜索并推荐符合新要求的选项。整个“<strong>查天气 → 调行程 → 订酒店</strong>”的流程,展现了其根据上下文动态修正自身行为的能力。
|
|
|
|
|
|
总而言之,我们正从开发专用自动化工具转向构建能自主解决问题的系统。核心不再是编写代码,而是引导一个通用的“大脑”去规划、行动和学习。
|
|
|
|
|
|
@@ -98,7 +98,7 @@
|
|
|
|
|
|
- <strong>混合式智能体(Hybrid Agents)</strong>
|
|
|
|
|
|
-现实世界的复杂任务,往往既需要即时反应,也需要长远规划。例如,一个火星探测车既要能快速躲避滚落的岩石(反应性),又要能规划抵达下一个考察点的长期路径(规划性)。因此,<strong>混合式智能体</strong>应运而生,它旨在结合两者的优点,实现反应与规划的平衡。
|
|
|
+现实世界的复杂任务,往往既需要即时反应,也需要长远规划。例如,我们之前提到的智能旅行助手,既要能根据用户的即时反馈(如“这家酒店太贵了”)调整推荐(反应性),又要能规划出为期数天的完整旅行方案(规划性)。因此,混合式智能体应运而生,它旨在结合两者的优点,实现反应与规划的平衡。
|
|
|
|
|
|
一种经典的混合架构是分层设计:底层是一个快速的反应模块,处理紧急情况和基本动作;高层则是一个审慎的规划模块,负责制定长远目标。而现代的LLM智能体,则展现了一种更灵活的混合模式。它们通常在一个“思考-行动-观察”的循环中运作,巧妙地将两种模式融为一体:
|
|
|
|
|
|
@@ -139,1062 +139,425 @@
|
|
|
|
|
|
人类的智能,正源于这两个系统的协同工作。同样,一个真正鲁棒的AI,也需要兼具二者之长。大语言模型驱动的智能体是神经符号主义的一个极佳实践范例。其内核是一个巨大的神经网络,使其具备模式识别和语言生成能力。然而,当它工作时,它会生成一系列结构化的中间步骤,如思想、计划或API调用,这些都是明确的、可操作的符号。通过这种方式,它实现了感知与认知、直觉与理性的初步融合。
|
|
|
|
|
|
-## 1.2 智能体与环境交互
|
|
|
|
|
|
-前一节我们讲解了智能体的不同类型。然而,仅有内部决策逻辑不足以实现目标,智能体必须通过与外部环境的持续互动来执行任务。其运作的核心是一个持续的<strong>智能体循环(Agent Loop)</strong>,它将复杂的任务分解为一系列标准的交互步骤,通常包括:
|
|
|
|
|
|
-1. <strong>感知(Perception)</strong> :智能体接收并解析来自用户或环境的输入信息,例如用户指令或上一步的行动结果。
|
|
|
-2. <strong>思考(Thought)</strong> :基于感知到的信息,智能体的核心模型进行规划,更新一个行动计划。这可能包括将复杂任务分解为子任务,或在众多可用工具中选择最合适的一个。
|
|
|
-3. <strong>行动(Action)</strong> :智能体调用选定的工具执行计划中的具体步骤,对环境施加影响。
|
|
|
-4. <strong>观察(Observation)</strong> :智能体评估行动产生的结果,并将其作为新一轮循环的输入,用以调整后续计划。
|
|
|
+## 1.2 智能体的构成与运行原理
|
|
|
|
|
|
-这个循环构成了所有LLM智能体运作的基本模式,如图1.5所示。1.2.1节将从环境的构成入手,进一步探讨该交互机制的属性及其对智能体设计的影响。
|
|
|
+### 1.2.1 任务环境定义
|
|
|
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-5.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.5 智能体与环境交互的基本循环</p>
|
|
|
-</div>
|
|
|
-
|
|
|
-### 1.2.1 任务环境的特性
|
|
|
-
|
|
|
-要理解智能体的运作,我们必须先理解它所处的<strong>任务环境</strong>。在人工智能领域,通常使用<strong>PEAS模型</strong>来精确描述一个任务环境,即分析其<strong>性能度量(Performance)、环境(Environment)、执行器(Actuators)和传感器(Sensors)</strong> 。以一个旅行规划智能体为例,下表1.2展示了如何运用PEAS模型对其任务环境进行规约。
|
|
|
+要理解智能体的运作,我们必须先理解它所处的<strong>任务环境</strong>。在人工智能领域,通常使用<strong>PEAS模型</strong>来精确描述一个任务环境,即分析其<strong>性能度量(Performance)、环境(Environment)、执行器(Actuators)和传感器(Sensors)</strong> 。以上文提到的智能旅行助手为例,下表1.2展示了如何运用PEAS模型对其任务环境进行规约。
|
|
|
|
|
|
<div align="center">
|
|
|
- <p>表 1.2 旅行规划智能体的PEAS描述</p>
|
|
|
+ <p>表 1.2 智能旅行助手的PEAS描述</p>
|
|
|
<img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-6.png" alt="图片描述" width="90%"/>
|
|
|
</div>
|
|
|
|
|
|
+
|
|
|
在实践中,LLM智能体所处的数字环境展现出若干复杂特性,这些特性直接影响着智能体的设计。
|
|
|
|
|
|
-首先,环境通常是<strong>部分可观察的</strong>。例如,一个购物智能体无法一次性看到所有商品信息,只能通过逐页访问来逐步构建对环境的认知,这就要求智能体必须具备记忆和状态追踪能力。
|
|
|
+首先,环境通常是<strong>部分可观察的</strong>。例如,旅行助手在查询航班时,无法一次性获取所有航空公司的全部实时座位信息。它只能通过调用航班预订API,看到该API返回的部分数据,这就要求智能体必须具备记忆(记住已查询过的航线)和探索(尝试不同的查询日期)的能力。
|
|
|
|
|
|
-其次,行动的结果也并非总是确定的。根据结果的可预测性,环境可分为<strong>确定性</strong>和<strong>随机性</strong>。当智能体执行本地代码进行数学计算时,结果是确定的;但当它调用一个实时变化的搜索引擎API时,结果便带有随机性,这就要求智能体必须具备容错和处理不确定性的能力。
|
|
|
+其次,行动的结果也并非总是确定的。根据结果的可预测性,环境可分为<strong>确定性</strong>和<strong>随机性</strong>。旅行助手的任务环境就是典型的随机性环境。当它搜索票价时,两次相邻的调用返回的机票价格和余票数量都可能不同,这就要求智能体必须具备处理不确定性、监控变化并及时决策的能力。
|
|
|
|
|
|
-此外,环境中还可能存在其他行动者,从而形成<strong>多智能体(Multi-agent)</strong> 环境。在这种情况下,智能体之间需要协作或竞争,一个智能体的行动会成为另一个智能体环境中的变量,这对智能体的沟通和协调能力提出了更高要求。
|
|
|
+此外,环境中还可能存在其他行动者,从而形成<strong>多智能体(Multi-agent)</strong> 环境。对于旅行助手而言,其他用户的预订行为、其他自动化脚本,甚至航司的动态调价系统,都是环境中的其他“智能体”。它们的行动(例如,订走最后一张特价票)会直接改变旅行助手所处环境的状态,这对智能体的快速响应和策略选择提出了更高要求。
|
|
|
|
|
|
最后,几乎所有任务都发生在<strong>序贯</strong>且<strong>动态</strong>的环境中。“序贯”意味着当前动作会影响未来;而“动态”则意味着环境自身可能在智能体决策时发生变化。这就要求智能体的“感知-思考-行动-观察”循环必须能够快速、灵活地适应持续变化的世界。
|
|
|
|
|
|
-### 1.2.2 环境交互的协议与接口
|
|
|
-
|
|
|
-LLM智能体与环境的互动需要一套明确的<strong>交互协议(Interaction Protocol)</strong>来规范信息的格式与流程。该协议的核心,体现在对智能体行动的结构化定义上。
|
|
|
-
|
|
|
-在诸如<strong>ReAct(Reasoning and Acting)</strong>等现代框架中,智能体的每一次输出通常是一段特殊格式的文本。其中不仅包含了要执行的行动本身,还明确展示了该行动之前的思考过程。
|
|
|
-
|
|
|
-这个“思考”部分是智能体内部决策的快照,它阐述了智能体如何<strong>分解任务</strong>、如何根据上一步的观察结果进行<strong>自我反思</strong>,以及最终决定下一步具体行动的<strong>策略规划</strong>。例如,一个正在规划旅行的智能体可能会生成如下格式化文本:
|
|
|
-
|
|
|
-```Bash
|
|
|
-Thought: 用户想知道北京的天气。我需要调用天气查询工具。
|
|
|
-Action: get_weather("北京")
|
|
|
-```
|
|
|
-
|
|
|
-这里的Action部分就是智能体对其执行器的指令。一个外部的解析器会捕捉到这个指令,并真正地去执行相应的`get_weather`函数。智能体的感知,即其传感
|
|
|
-
|
|
|
-器的输入,则是上述行动执行后的结果。当外部工具执行完`get_weather("北京")`后,它可能得到一个包含温度、湿度、风力等信息的JSON对象。这个原始数据对于LLM来说过于冗长和非自然。因此,传感器的角色需要将这个JSON对象处理并封装成一段清晰、简洁的自然语言文本,例如:
|
|
|
+### 1.2.2 智能体的运行机制
|
|
|
|
|
|
-```Bash
|
|
|
-Observation: 北京当前天气为晴,气温25摄氏度,微风。
|
|
|
-```
|
|
|
+在定义了智能体所处的任务环境后,我们来探讨其核心的运行机制。智能体并非一次性完成任务,而是通过一个持续的循环与环境进行交互,这个核心机制被称为 <strong>智能体循环 (Agent Loop)</strong>。如图1.5所示,该循环描述了智能体与环境之间的动态交互过程,构成了其自主行为的基础。
|
|
|
|
|
|
-这段Observation文本会被拼接在下一轮提供给LLM的输入中,成为其后续进行新一轮思考和行动的依据。
|
|
|
+<div align="center">
|
|
|
+ <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-5.png" alt="图片描述" width="90%"/>
|
|
|
+ <p>图 1.5 智能体与环境交互的基本循环</p>
|
|
|
+</div>
|
|
|
|
|
|
-通过这个由`Thought`, `Action`, `Observation`构成的循环,LLM智能体得以将内部的语言推理能力,与外部环境的真实信息和工具操作能力结合起来,从而在一个明确的接口上,完成对复杂任务的逐步拆解和执行。因此,设计一个清晰、稳定且功能恰当的工具接口,是实现有效LLM智能体行为的工程学前提。
|
|
|
+这个循环主要包含以下几个相互关联的阶段:
|
|
|
|
|
|
-<strong>标准化接口组件定义</strong>
|
|
|
+1. <strong>感知 (Perception)</strong>:这是循环的起点。智能体通过其传感器(例如,API的监听端口、用户输入接口)接收来自环境的输入信息。这些信息,即<strong>观察 (Observation)</strong>,既可以是用户的初始指令,也可以是上一步行动所导致的环境状态变化反馈。
|
|
|
+2. <strong>思考 (Thought)</strong>:接收到观察信息后,智能体进入其核心决策阶段。对于LLM智能体而言,这通常是由大语言模型驱动的内部推理过程。如图所示,“思考”阶段可进一步细分为两个关键环节:
|
|
|
+ - <strong>规划 (Planning)</strong>:智能体基于当前的观察和其内部记忆,更新对任务和环境的理解,并制定或调整一个行动计划。这可能涉及将复杂目标分解为一系列更具体的子任务。
|
|
|
+ - <strong>工具选择 (Tool Selection)</strong>:根据当前计划,智能体从其可用的工具库中,选择最适合执行下一步骤的工具,并确定调用该工具所需的具体参数。
|
|
|
+3. <strong>行动 (Action)</strong>:决策完成后,智能体通过其执行器(Actuators)执行具体的行动。这通常表现为调用一个选定的工具(如代码解释器、搜索引擎API),从而对环境施加影响,意图改变环境的状态。
|
|
|
|
|
|
-`Perception-Thought-Action-Observation` 循环是通过一套标准化的接口组件来实现的。为确保系统的可扩展性与可维护性,这些接口遵循单一职责原则,分别对应循环中的一个关键环节。下面我们将对这四个核心组件进行定义。
|
|
|
+行动并非循环的终点。智能体的行动会引起<strong>环境 (Environment)</strong> 的<strong>状态变化 (State Change)</strong>,环境随即会产生一个新的<strong>观察 (Observation)</strong> 作为结果反馈。这个新的观察又会在下一轮循环中被智能体的感知系统捕获,形成一个持续的“感知-思考-行动-观察”的闭环。智能体正是通过不断重复这一循环,逐步推进任务,从初始状态向目标状态演进。
|
|
|
|
|
|
-<strong>接口1:感知器</strong>
|
|
|
+### 1.2.3 智能体的感知与行动
|
|
|
|
|
|
-感知器负责处理输入信息,将原始数据转化为智能体可理解的格式:
|
|
|
+在工程实践中,为了让LLM能够有效驱动这个循环,我们需要一套明确的<strong>交互协议 (Interaction Protocol)</strong> 来规范其与环境之间的信息交换。
|
|
|
|
|
|
-~~~Python
|
|
|
-class PerceptionInterface:
|
|
|
- """感知器接口:处理输入信息,理解用户意图"""
|
|
|
-
|
|
|
- def process_user_input(self, user_input: str, context: list) -> dict:
|
|
|
- """
|
|
|
- 处理用户输入,提取关键信息
|
|
|
- 参数: user_input - 用户原始输入, context - 历史上下文
|
|
|
- 返回: {"intent": "意图", "entities": "实体", "processed_text": "处理后文本"}
|
|
|
- """
|
|
|
- pass
|
|
|
-
|
|
|
- def update_context(self, new_info: str) -> None:
|
|
|
- """更新上下文信息"""
|
|
|
- pass
|
|
|
-```
|
|
|
-~~~
|
|
|
+在许多现代智能体框架中,这一协议体现在对智能体每一次输出的结构化定义上。智能体的输出不再是单一的自然语言回复,而是一段遵循特定格式的文本,其中明确地展示了其内部的推理过程与最终决策。
|
|
|
|
|
|
-<strong>接口2:思考器</strong>
|
|
|
+这个结构通常包含两个核心部分:
|
|
|
|
|
|
-思考器基于感知结果进行推理和规划:
|
|
|
+- <strong>Thought (思考)</strong>:这是智能体内部决策的“快照”。它以自然语言形式阐述了智能体如何分析当前情境、回顾上一步的观察结果、进行自我反思与问题分解,并最终规划出下一步的具体行动。
|
|
|
+- <strong>Action (行动)</strong>:这是智能体基于思考后,决定对环境施加的具体操作,通常以函数调用的形式表示。
|
|
|
|
|
|
-```Python
|
|
|
-class ThinkingInterface:
|
|
|
- """思考器接口:基于感知结果进行推理和规划"""
|
|
|
-
|
|
|
- def analyze_situation(self, perception_result: dict) -> str:
|
|
|
- """
|
|
|
- 分析当前情况
|
|
|
- 参数: perception_result - 感知器的处理结果
|
|
|
- 返回: 情况分析文本
|
|
|
- """
|
|
|
- pass
|
|
|
-
|
|
|
- def generate_plan(self, analysis: str, available_tools: list) -> dict:
|
|
|
- """
|
|
|
- 生成执行计划
|
|
|
- 返回: {"thought": "思考过程", "action": "计划行动", "tool": "选择工具", "params": "参数"}
|
|
|
- """
|
|
|
- pass
|
|
|
-```
|
|
|
+例如,一个正在规划旅行的智能体可能会生成如下格式化的输出:
|
|
|
|
|
|
-<strong>接口3:执行器</strong>
|
|
|
-
|
|
|
-执行器负责将计划转化为具体的工具调用:
|
|
|
-
|
|
|
-```Python
|
|
|
-class ExecutionInterface:
|
|
|
- """执行器接口:执行具体的工具调用"""
|
|
|
-
|
|
|
- def execute_tool(self, tool_name: str, parameters: dict) -> dict:
|
|
|
- """
|
|
|
- 执行指定工具
|
|
|
- 返回: {"success": bool, "data": "执行结果", "error": "错误信息(如有)"}
|
|
|
- """
|
|
|
- pass
|
|
|
-
|
|
|
- def register_tool(self, name: str, tool_function) -> None:
|
|
|
- """注册新工具"""
|
|
|
- pass
|
|
|
+```Bash
|
|
|
+Thought: 用户想知道北京的天气。我需要调用天气查询工具。
|
|
|
+Action: get_weather("北京")
|
|
|
```
|
|
|
|
|
|
-<strong>接口4:观察器</strong>
|
|
|
+这里的`Action`字段构成了对外部世界的指令。一个外部的<strong>解析器 (Parser)</strong> 会捕捉到这个指令,并调用相应的`get_weather`函数。
|
|
|
|
|
|
-观察器处理执行结果,生成反馈信息:
|
|
|
+行动执行后,环境会返回一个结果。例如,`get_weather`函数可能返回一个包含详细天气数据的JSON对象。然而,原始的机器可读数据(如JSON)通常包含LLM无需关注的冗余信息,且格式不符合其自然语言处理的习惯。
|
|
|
|
|
|
-```Python
|
|
|
-class ObservationInterface:
|
|
|
- """观察器接口:处理执行结果,生成观察反馈"""
|
|
|
-
|
|
|
- def process_result(self, execution_result: dict, original_plan: dict) -> dict:
|
|
|
- """
|
|
|
- 处理执行结果
|
|
|
- 返回: {"observation": "观察文本", "success": bool, "next_action": "下一步建议"}
|
|
|
- """
|
|
|
- pass
|
|
|
-
|
|
|
- def format_response(self, observation: dict) -> str:
|
|
|
- """格式化最终用户回复"""
|
|
|
- pass
|
|
|
-```
|
|
|
-
|
|
|
-<strong>统一的智能体接口</strong>
|
|
|
-
|
|
|
-这四个组件通过一个统一的智能体接口进行协调:
|
|
|
+因此,感知系统的一个重要职责就是扮演传感器的角色:将这个原始输出处理并封装成一段简洁、清晰的自然语言文本,即观察。
|
|
|
|
|
|
-```Python
|
|
|
-class AgentInterface:
|
|
|
- """智能体统一接口:协调四个核心组件"""
|
|
|
-
|
|
|
- def __init__(self):
|
|
|
- self.perception = None # 感知器实例
|
|
|
- self.thinking = None # 思考器实例
|
|
|
- self.execution = None # 执行器实例
|
|
|
- self.observation = None # 观察器实例
|
|
|
-
|
|
|
- def process_request(self, user_input: str) -> str:
|
|
|
- """
|
|
|
- 处理用户请求的完整流程
|
|
|
- 返回: 最终回复给用户的文本
|
|
|
- """
|
|
|
- # 1. 感知 -> 2. 思考 -> 3. 执行 -> 4. 观察
|
|
|
- pass
|
|
|
+```Bash
|
|
|
+Observation: 北京当前天气为晴,气温25摄氏度,微风。
|
|
|
```
|
|
|
|
|
|
-这些接口定义为后续的具体实现提供了规范。每个接口都有明确的输入输出格式,确保了组件间的解耦和系统的可扩展性。在接下来的1.2.3节中,我们将逐步实现这些接口(分别为`PerceptionImpl`、`ThinkingImpl`、`ExecutionImpl`、`ObservationImpl`),并最终组装成一个完整的智能体的基本示例。
|
|
|
-
|
|
|
-### 1.2.3 智能体的行动循环
|
|
|
+这段`Observation`文本会被反馈给智能体,作为下一轮循环的主要输入信息,供其进行新一轮的`Thought`和`Action`。
|
|
|
|
|
|
-智能体的行动循环是其自主性的核心体现。它是一个从信息输入(感知),经过内部状态转换(思考),到行为输出(行动),再到结果反馈(观察)的完整闭环。这个持续运行的流程,确保了智能体能够响应外部世界,并根据结果动态调整其行为。
|
|
|
+综上所述,通过这个由Thought、Action、Observation构成的严谨循环,LLM智能体得以将内部的语言推理能力,与外部环境的真实信息和工具操作能力有效地结合起来。
|
|
|
|
|
|
-这里有必要澄清一个关键点:通常被描述为“思考-行动-观察”的循环,为何在这里以“感知”作为第一步。可以这样理解:思考-行动-观察是智能体内部的核心认知循环。然而,这个循环必须由一个外部刺激来启动。感知与理解阶段正是处理这种外部刺激的入口,它负责将外部数据转化为智能体内部可以处理的格式,从而触发核心认知循环的第一次迭代。
|
|
|
+## 1.3 动手体验:5 分钟实现第一个智能体
|
|
|
|
|
|
-接下来,我们将把这个循环分解为四个逻辑阶段,并逐一探讨实现这些阶段所需的核心组件。
|
|
|
+在前面的小节,我们学习了智能体的任务环境、核心运行机制以及 `Thought-Action-Observation` 交互范式。理论知识固然重要,但最好的学习方式是亲手实践。在本节中,我们将引导您使用几行简单的Python代码,从零开始构建一个可以工作的智能旅行助手。这个过程将遵循我们刚刚学到的理论循环,让您直观地感受到一个智能体是如何“思考”并与外部“工具”互动的。让我们开始吧!
|
|
|
|
|
|
-<strong>第一步:感知与理解</strong>
|
|
|
+在本案例中,我们的目标是构建一个能处理分步任务的智能旅行助手。需要解决的用户任务定义为:"你好,请帮我查询一下今天北京的天气,然后根据天气推荐一个合适的旅游景点。"要完成这个任务,智能体必须展现出清晰的逻辑规划能力。它需要先调用天气查询工具,并将获得的观察结果作为下一步的依据。在下一轮循环中,它再调用景点推荐工具,从而得出最终建议。
|
|
|
|
|
|
-感知是整个信息处理流程的起点,是智能体接收外部输入的接口。其核心职责是将来自外部世界的原始、非结构化数据(如用户的自然语言查询、API的JSON响应等),转换为后续模块(尤其是思考模块)能够处理的结构化内部表述 (Internal Representation)。
|
|
|
+### 1.3.1 准备工作
|
|
|
|
|
|
-此阶段的输出质量直接决定了智能体后续所有决策的上限。一个精确的感知模块能够准确地捕捉意图、提取关键参数,为高质量的规划奠定基础。
|
|
|
+为了能从Python程序中访问网络API,我们需要一个HTTP库。`requests`是Python社区中最流行、最易用的选择。请先通过以下命令安装它:
|
|
|
|
|
|
-在 `PerceptionImpl` 类的实现中,`process_user_input` 方法承担了此项职能。它接收原始输入字符串,通过意图识别和实体提取等技术,将其转换为一个包含 `intent` 和 `entities` 键的字典。这个过程是自然语言理解的一个简化示例。
|
|
|
-
|
|
|
-```Python
|
|
|
-class PerceptionImpl:
|
|
|
- """感知器接口的简化实现,负责将外部输入结构化"""
|
|
|
-
|
|
|
- def __init__(self):
|
|
|
- self.context = [] # 存储历史交互信息
|
|
|
-
|
|
|
- def process_user_input(self, user_input: str, context: list) -> dict:
|
|
|
- """处理用户输入,将其从自然语言转化为结构化的意图和实体。"""
|
|
|
- # 模拟意图识别
|
|
|
- intent = "unknown"
|
|
|
- entities = {}
|
|
|
-
|
|
|
- if "天气" in user_input:
|
|
|
- intent = "weather_query"
|
|
|
- # 模拟实体提取
|
|
|
- if "北京" in user_input:
|
|
|
- entities["city"] = "北京"
|
|
|
- elif "上海" in user_input:
|
|
|
- entities["city"] = "上海"
|
|
|
- else:
|
|
|
- entities["city"] = "未知城市"
|
|
|
-
|
|
|
- return {
|
|
|
- "intent": intent,
|
|
|
- "entities": entities,
|
|
|
- "processed_text": f"用户意图被解析为:{intent},相关实体:{entities}",
|
|
|
- "original_input": user_input
|
|
|
- }
|
|
|
-
|
|
|
- def update_context(self, new_info: str) -> None:
|
|
|
- """更新上下文信息"""
|
|
|
- self.context.append(new_info)
|
|
|
- # 维持上下文队列的固定长度
|
|
|
- if len(self.context) > 5:
|
|
|
- self.context.pop(0)
|
|
|
+```bash
|
|
|
+pip install requests tavily-python openai
|
|
|
```
|
|
|
|
|
|
-<strong>第二步:思考与规划</strong>
|
|
|
-
|
|
|
-思考与规划模块是智能体的决策单元。它接收来自感知模块的结构化信息,基于当前状态和可用资源(如工具集)进行推理、分析、任务分解,并最终制定出具体的行动计划。
|
|
|
+(1)指令模板
|
|
|
|
|
|
-此阶段的产出是一个明确的行动指令,它通常包含两部分:智能体进行决策的思考过程和具体的执行方案。`Thought` 提供了决策的可解释性,记录了智能体“为什么”这么做。`Plan` 则清晰地定义了“做什么”(例如,调用哪个工具)和“怎么做”(例如,需要哪些参数)。
|
|
|
+驱动真实LLM的关键在于<strong>提示工程(Prompt Engineering)</strong>。我们需要设计一个“指令模板”,告诉LLM它应该扮演什么角色、拥有哪些工具、以及如何格式化它的思考和行动。这是我们智能体的“说明书”,它将作为`system_prompt`传递给LLM。
|
|
|
|
|
|
-`ThinkingImpl` 类演示了这一核心功能。`analyze_situation` 方法根据感知结果生成分析,即`Thought`。`generate_plan` 方法则基于该分析和可用的工具列表,生成一个包含目标工具和所需参数的结构化指令。
|
|
|
-
|
|
|
-```Python
|
|
|
-class ThinkingImpl:
|
|
|
- """思考器接口的简化实现,智能体的核心决策单元"""
|
|
|
-
|
|
|
- def analyze_situation(self, perception_result: dict) -> str:
|
|
|
- """分析感知结果,形成内在的推理链(Thought)。"""
|
|
|
- intent = perception_result["intent"]
|
|
|
- entities = perception_result["entities"]
|
|
|
-
|
|
|
- if intent == "weather_query":
|
|
|
- city = entities.get("city", "未知城市")
|
|
|
- return f"识别到用户意图为查询天气,目标城市为{city}。需要调用天气查询工具。"
|
|
|
- else:
|
|
|
- return "未能识别明确的用户意图,无法制定下一步计划。"
|
|
|
-
|
|
|
- def generate_plan(self, analysis: str, available_tools: list) -> dict:
|
|
|
- """基于推理分析,生成结构化的执行计划(Action)。"""
|
|
|
- if "天气查询工具" in analysis and "get_weather" in available_tools:
|
|
|
- # 此处为简化处理,实际场景中需要更鲁棒的参数提取逻辑
|
|
|
- city = "北京"
|
|
|
- if "上海" in analysis:
|
|
|
- city = "上海"
|
|
|
-
|
|
|
- return {
|
|
|
- "thought": analysis,
|
|
|
- "action": "invoke_tool",
|
|
|
- "tool": "get_weather",
|
|
|
- "params": {"city": city}
|
|
|
- }
|
|
|
- else:
|
|
|
- return {
|
|
|
- "thought": analysis,
|
|
|
- "action": "no_action",
|
|
|
- "tool": None,
|
|
|
- "params": {}
|
|
|
- }
|
|
|
```
|
|
|
+AGENT_SYSTEM_PROMPT = """
|
|
|
+你是一个智能旅行助手。你的任务是分析用户的请求,并使用可用工具一步步地解决问题。
|
|
|
|
|
|
-<strong>第三步:执行与操作</strong>
|
|
|
+# 可用工具:
|
|
|
+- `get_weather(city: str)`: 查询指定城市的实时天气。
|
|
|
+- `get_attraction(city: str, weather: str)`: 根据城市和天气搜索推荐的旅游景点。
|
|
|
|
|
|
-执行模块是连接智能体内部决策与外部世界的桥梁,是行动指令的实现层。它负责解析思考模块生成的行动计划,并调用相应的工具(如函数、API、数据库查询等)来完成具体任务。该模块使得智能体能够对外部环境产生实际影响或从中获取信息。执行结果的成功与否、返回的数据或错误信息,将成为下一阶段“观察”模块的关键输入。
|
|
|
+# 行动格式:
|
|
|
+你的回答必须严格遵循以下格式。首先是你的思考过程,然后是你要执行的具体行动。
|
|
|
+Thought: [这里是你的思考过程和下一步计划]
|
|
|
+Action: [这里是你要调用的工具,格式为 function_name(arg_name="arg_value")]
|
|
|
|
|
|
-`ExecutionImpl` 类扮演了执行器的角色。它通过一个工具注册表 (`self.tools`) 维护所有可用的工具。`execute_tool` 方法则充当调度器,根据指定的工具名称和参数,调用相应的函数,并以标准化的格式返回执行结果。
|
|
|
+# 任务完成:
|
|
|
+当你收集到足够的信息,能够回答用户的最终问题时,你必须使用 `finish(answer="...")` 来输出最终答案。
|
|
|
|
|
|
-```Python
|
|
|
-class ExecutionImpl:
|
|
|
- """执行器接口的简化实现,负责调用工具并与外部环境交互"""
|
|
|
-
|
|
|
- def __init__(self):
|
|
|
- self.tools = {}
|
|
|
- # 注册一个默认工具
|
|
|
- self.register_tool("get_weather", self._get_weather_tool)
|
|
|
-
|
|
|
- def execute_tool(self, tool_name: str, parameters: dict) -> dict:
|
|
|
- """执行指定的工具,并返回标准化的结果对象。"""
|
|
|
- if tool_name not in self.tools:
|
|
|
- return {
|
|
|
- "success": False,
|
|
|
- "data": None,
|
|
|
- "error": f"工具 '{tool_name}' 未注册。"
|
|
|
- }
|
|
|
-
|
|
|
- try:
|
|
|
- result = self.tools[tool_name](<strong>parameters)
|
|
|
- return {
|
|
|
- "success": True,
|
|
|
- "data": result,
|
|
|
- "error": None
|
|
|
- }
|
|
|
- except Exception as e:
|
|
|
- return {
|
|
|
- "success": False,
|
|
|
- "data": None,
|
|
|
- "error": f"执行工具 '{tool_name}' 时发生异常: {e}"
|
|
|
- }
|
|
|
-
|
|
|
- def register_tool(self, name: str, tool_function) -> None:
|
|
|
- """注册一个新工具,使其可被执行器调用。"""
|
|
|
- self.tools[name] = tool_function
|
|
|
-
|
|
|
- def _get_weather_tool(self, city: str) -> str:
|
|
|
- """一个模拟的天气查询工具API。"""
|
|
|
- weather_data = {
|
|
|
- "北京": "天气晴朗,温度25摄氏度,风力2级。",
|
|
|
- "上海": "多云转阴,温度22摄氏度,风力3级。"
|
|
|
- }
|
|
|
- return weather_data.get(city, f"未能查询到 {city} 的天气信息。")
|
|
|
+请开始吧!
|
|
|
+"""
|
|
|
```
|
|
|
|
|
|
-<strong>第四步:观察与学习</strong>
|
|
|
-
|
|
|
-行动的完成并不意味着流程的结束,而是形成反馈闭环的关键一步。观察模块负责接收和评估执行阶段的输出,并将其转化为智能体内部可以理解的观察结果。
|
|
|
-
|
|
|
-此阶段的核心功能是:
|
|
|
+(2)工具1:查询真实天气
|
|
|
|
|
|
-1. <strong>评估行动结果</strong>:判定上一步行动的成败,并解析成功时返回的数据或失败时产生的错误信息。
|
|
|
-2. <strong>决策后续流程</strong>:根据评估结果,确定下一步的走向。例如,成功获取数据则准备向用户响应;失败则可能需要将错误信息反馈给思考模块以进行重新规划。
|
|
|
+我们将使用免费的天气查询服务 `wttr.in`,它能以JSON格式返回指定城市的天气数据。下面是实现该工具的代码:
|
|
|
|
|
|
-这个观察结果将作为新的信息输入,反馈给认知循环的下一个迭代,从而使智能体能够根据其行为的实际效果来调整后续策略。
|
|
|
+```python
|
|
|
+import requests
|
|
|
+import json
|
|
|
|
|
|
-在 `ObservationImpl` 的实现中,`process_result` 方法负责将执行结果转化为结构化的观察结论,而 `format_response` 则用于将最终结论格式化为面向用户的输出。
|
|
|
-
|
|
|
-```Python
|
|
|
-class ObservationImpl:
|
|
|
- """观察器接口的简化实现,负责评估执行结果并形成反馈"""
|
|
|
-
|
|
|
- def process_result(self, execution_result: dict, original_plan: dict) -> dict:
|
|
|
- """处理执行结果,生成结构化的观察结论。"""
|
|
|
- if execution_result["success"]:
|
|
|
- observation_text = f"动作 '{original_plan['action']}' 执行成功,获取数据:{execution_result['data']}"
|
|
|
- return {
|
|
|
- "observation": observation_text,
|
|
|
- "success": True,
|
|
|
- "next_action": "respond_to_user"
|
|
|
- }
|
|
|
- else:
|
|
|
- observation_text = f"动作 '{original_plan['action']}' 执行失败,错误信息:{execution_result['error']}"
|
|
|
- return {
|
|
|
- "observation": observation_text,
|
|
|
- "success": False,
|
|
|
- "next_action": "error_handling"
|
|
|
- }
|
|
|
+def get_weather(city: str) -> str:
|
|
|
+ """
|
|
|
+ 通过调用 wttr.in API 查询真实的天气信息。
|
|
|
+ """
|
|
|
+ # API端点,我们请求JSON格式的数据
|
|
|
+ url = f"https://wttr.in/{city}?format=j1"
|
|
|
|
|
|
- def format_response(self, observation: dict) -> str:
|
|
|
- """根据最终的观察结果,格式化对用户的回复。"""
|
|
|
- if observation["success"]:
|
|
|
- # 从观察文本中提取核心数据进行回复
|
|
|
- return f"根据查询,{observation['observation'].split(':')[1]}"
|
|
|
- else:
|
|
|
- return f"处理请求时出错:{observation['observation'].split(':')[1]}"
|
|
|
+ try:
|
|
|
+ # 发起网络请求
|
|
|
+ response = requests.get(url)
|
|
|
+ # 检查响应状态码是否为200 (成功)
|
|
|
+ response.raise_for_status()
|
|
|
+ # 解析返回的JSON数据
|
|
|
+ data = response.json()
|
|
|
+
|
|
|
+ # 提取当前天气状况
|
|
|
+ current_condition = data['current_condition'][0]
|
|
|
+ weather_desc = current_condition['weatherDesc'][0]['value']
|
|
|
+ temp_c = current_condition['temp_C']
|
|
|
+
|
|
|
+ # 格式化成自然语言返回
|
|
|
+ return f"{city}当前天气:{weather_desc},气温{temp_c}摄氏度"
|
|
|
+
|
|
|
+ except requests.exceptions.RequestException as e:
|
|
|
+ # 处理网络错误
|
|
|
+ return f"错误:查询天气时遇到网络问题 - {e}"
|
|
|
+ except (KeyError, IndexError) as e:
|
|
|
+ # 处理数据解析错误
|
|
|
+ return f"错误:解析天气数据失败,可能是城市名称无效 - {e}"
|
|
|
```
|
|
|
|
|
|
-<strong>完整的智能体行动循环演示</strong>
|
|
|
+(3)工具2:搜索并推荐旅游景点
|
|
|
|
|
|
-最后,我们将上述四个独立的模块化组件进行集成,构建一个完整的 `AgentLoopDemo`。这个类展示了四个阶段如何被依次调用和协同工作,形成一个从接收原始输入到生成最终响应的、端到端的处理流水线,具体流程如图1.6所示。
|
|
|
+我们将定义一个新工具 `search_attraction`,它会根据城市和天气状况,互联网上搜索合适的景点:
|
|
|
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-7.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.6 智能体行动循环的实现流程</p>
|
|
|
-</div>
|
|
|
+```python
|
|
|
+import os
|
|
|
+from tavily import TavilyClient
|
|
|
|
|
|
-每一次对 `process_request` 方法的调用,都代表了一次完整的“感知-思考-执行-观察”循环的执行过程。
|
|
|
+def get_attraction(city: str, weather: str) -> str:
|
|
|
+ """
|
|
|
+ 根据城市和天气,使用Tavily Search API搜索并返回优化后的景点推荐。
|
|
|
+ """
|
|
|
+ # 1. 从环境变量中读取API密钥
|
|
|
+ api_key = os.environ.get("TAVILY_API_KEY")
|
|
|
+ if not api_key:
|
|
|
+ return "错误:未配置TAVILY_API_KEY环境变量。"
|
|
|
|
|
|
-```Python
|
|
|
-class AgentLoopDemo:
|
|
|
- """智能体行动循环演示:集成四个核心组件的完整示例"""
|
|
|
+ # 2. 初始化Tavily客户端
|
|
|
+ tavily = TavilyClient(api_key=api_key)
|
|
|
|
|
|
- def __init__(self):
|
|
|
- self.perception = PerceptionImpl()
|
|
|
- self.thinking = ThinkingImpl()
|
|
|
- self.execution = ExecutionImpl()
|
|
|
- self.observation = ObservationImpl()
|
|
|
+ # 3. 构造一个精确的查询
|
|
|
+ query = f"'{city}' 在'{weather}'天气下最值得去的旅游景点推荐及理由"
|
|
|
|
|
|
- def process_request(self, user_input: str) -> str:
|
|
|
- """处理用户请求的完整流程"""
|
|
|
- print(f"\n[Input] 用户请求: {user_input}")
|
|
|
-
|
|
|
- # 阶段 1: 感知与理解 (Perception)
|
|
|
- perception_result = self.perception.process_user_input(user_input, self.perception.context)
|
|
|
- print(f"[Perception] 解析结果: {perception_result['processed_text']}")
|
|
|
-
|
|
|
- # 阶段 2: 思考与规划 (Thinking)
|
|
|
- analysis = self.thinking.analyze_situation(perception_result)
|
|
|
- available_tools = list(self.execution.tools.keys())
|
|
|
- plan = self.thinking.generate_plan(analysis, available_tools)
|
|
|
- print(f"[Thinking] 推理过程: {plan['thought']}")
|
|
|
- print(f"[Planning] 行动计划: {plan['action']} -> Tool: {plan['tool']}, Params: {plan['params']}")
|
|
|
-
|
|
|
- # 阶段 3: 执行与操作 (Execution)
|
|
|
- if plan["tool"]:
|
|
|
- execution_result = self.execution.execute_tool(plan["tool"], plan["params"])
|
|
|
- print(f"[Execution] 执行结果: {'Success' if execution_result['success'] else 'Failure'}, Details: {execution_result['data'] or execution_result['error']}")
|
|
|
- else:
|
|
|
- execution_result = {"success": False, "data": None, "error": "无可用行动计划"}
|
|
|
- print(f"[Execution] 执行结果: {execution_result['error']}")
|
|
|
-
|
|
|
- # 阶段 4: 观察与学习 (Observation)
|
|
|
- observation_result = self.observation.process_result(execution_result, plan)
|
|
|
- print(f"[Observation] 观察结论: {observation_result['observation']}")
|
|
|
+ try:
|
|
|
+ # 4. 调用API,include_answer=True会返回一个综合性的回答
|
|
|
+ response = tavily.search(query=query, search_depth="basic", include_answer=True)
|
|
|
|
|
|
- # 生成最终响应
|
|
|
- final_response = self.observation.format_response(observation_result)
|
|
|
- print(f"[Output] 最终回答: {final_response}")
|
|
|
+ # 5. Tavily返回的结果已经非常干净,可以直接使用
|
|
|
+ # response['answer'] 是一个基于所有搜索结果的总结性回答
|
|
|
+ if response.get("answer"):
|
|
|
+ return response["answer"]
|
|
|
|
|
|
- # 更新上下文,用于潜在的后续交互
|
|
|
- self.perception.update_context(f"User: '{user_input}', Agent: '{final_response}'")
|
|
|
+ # 如果没有综合性回答,则格式化原始结果
|
|
|
+ formatted_results = []
|
|
|
+ for result in response.get("results", []):
|
|
|
+ formatted_results.append(f"- {result['title']}: {result['content']}")
|
|
|
|
|
|
- return final_response
|
|
|
+ if not formatted_results:
|
|
|
+ return "抱歉,没有找到相关的旅游景点推荐。"
|
|
|
|
|
|
-# 运行示例
|
|
|
-if __name__ == "__main__":
|
|
|
- agent = AgentLoopDemo()
|
|
|
-
|
|
|
- test_cases = [
|
|
|
- "我想知道北京今天的天气",
|
|
|
- "查询上海的天气情况",
|
|
|
- "今天心情不错" # 无法处理的请求
|
|
|
- ]
|
|
|
-
|
|
|
- for test_input in test_cases:
|
|
|
- result = agent.process_request(test_input)
|
|
|
- print("-" * 60)
|
|
|
-
|
|
|
-
|
|
|
-# 运行效果演示
|
|
|
-当我们运行这个完整示例时,可以看到清晰的四步处理流程:
|
|
|
-
|
|
|
->>>
|
|
|
-[Input] 用户请求: 我想知道北京今天的天气
|
|
|
-[Perception] 解析结果: 用户意图被解析为:weather_query,相关实体:{'city': '北京'}
|
|
|
-[Thinking] 推理过程: 识别到用户意图为查询天气,目标城市为北京。需要调用天气查询工具。
|
|
|
-[Planning] 行动计划: invoke_tool -> Tool: get_weather, Params: {'city': '北京'}
|
|
|
-[Execution] 执行结果: Success, Details: 天气晴朗,温度25摄氏度,风力2级。
|
|
|
-[Observation] 观察结论: 动作 'invoke_tool' 执行成功,获取数据:天气晴朗,温度25摄氏度,风力2级。
|
|
|
-[Output] 最终回答: 根据查询,天气晴朗,温度25摄氏度,风力2级。
|
|
|
-------------------------------------------------------------
|
|
|
-
|
|
|
-[Input] 用户请求: 查询上海的天气情况
|
|
|
-[Perception] 解析结果: 用户意图被解析为:weather_query,相关实体:{'city': '上海'}
|
|
|
-[Thinking] 推理过程: 识别到用户意图为查询天气,目标城市为上海。需要调用天气查询工具。
|
|
|
-[Planning] 行动计划: invoke_tool -> Tool: get_weather, Params: {'city': '上海'}
|
|
|
-[Execution] 执行结果: Success, Details: 多云转阴,温度22摄氏度,风力3级。
|
|
|
-[Observation] 观察结论: 动作 'invoke_tool' 执行成功,获取数据:多云转阴,温度22摄氏度,风力3级。
|
|
|
-[Output] 最终回答: 根据查询,多云转阴,温度22摄氏度,风力3级。
|
|
|
-------------------------------------------------------------
|
|
|
-
|
|
|
-[Input] 用户请求: 今天心情不错
|
|
|
-[Perception] 解析结果: 用户意图被解析为:unknown,相关实体:{}
|
|
|
-[Thinking] 推理过程: 未能识别明确的用户意图,无法制定下一步计划。
|
|
|
-[Planning] 行动计划: no_action -> Tool: None, Params: {}
|
|
|
-[Execution] 执行结果: 无可用行动计划
|
|
|
-[Observation] 观察结论: 动作 'no_action' 执行失败,错误信息:无可用行动计划
|
|
|
-[Output] 最终回答: 处理请求时出错:无可用行动计划
|
|
|
-------------------------------------------------------------
|
|
|
-```
|
|
|
+ return "根据搜索,为您找到以下信息:\n" + "\n".join(formatted_results)
|
|
|
|
|
|
-### 1.2.4 典型环境中的智能体案例
|
|
|
-
|
|
|
-在前述的 1.2.1 至 1.2.3 小节中,我们已经为智能体与环境的交互补充了理论基础:从任务环境的宏观介绍,到交互协议与接口的具体定义,再到一个基础智能体行动循环的实现。为了具体地了解智能体是如何在不同特性的环境中进行感知、规划与行动的,在本案例中,我们将构建一个实际的网络信息检索智能体。
|
|
|
-
|
|
|
-准备工作:在开始编码之前,我们需要先安装几个Python库。
|
|
|
-
|
|
|
-- `ddgs`: 这是一个用于调用DuckDuckGo搜索引擎的客户端库,我们可以无需使用API来进行基本的搜索网页功能实现。
|
|
|
-- `openai`: openai 提供了统一的 API 接口格式,简化了我们与多种大语言模型(LLM)交互的流程,可以选择自己所拥有的API进行适配。
|
|
|
-- `requests`: 这是Python中处理网络请求的基础库,`openai`库依赖它来发送和接收数据。
|
|
|
-
|
|
|
-请打开你的终端(命令行工具),然后运行下面的命令来安装它们:
|
|
|
-
|
|
|
-```Bash
|
|
|
-pip install ddgs openai requests
|
|
|
+ except Exception as e:
|
|
|
+ return f"错误:执行Tavily搜索时出现问题 - {e}"
|
|
|
```
|
|
|
|
|
|
-智能体需要一个核心组件来理解和生成语言,这个角色由LLM承担。考虑到LLM服务的多样性,为了保证代码的模块化与可扩展性,我们首先创建一个统一的<strong>客户端(Client)</strong>来封装与LLM的交互。首先,我们定义一个标准接口。在面向对象编程中,这通常通过<strong>抽象基类(Abstract Base Class)</strong>来实现。该基类定义了一个所有LLM客户端都必须遵守的规范,即它们都必须实现一个名为 `generate` 的方法。这种设计模式确保了主逻辑的稳定性:无论未来底层实现如何变更,主程序都依赖于统一的接口进行调用。
|
|
|
+最后,我们将所有工具函数放入一个字典,供主循环调用:
|
|
|
|
|
|
-```Python
|
|
|
-class BaseLLM:
|
|
|
- """
|
|
|
- 定义所有LLM客户端都应遵循的基本接口。
|
|
|
- 这是一个抽象基类,用于确保所有子类都有一个 generate 方法。
|
|
|
- """
|
|
|
- def generate(self, prompt: str) -> str:
|
|
|
- """根据输入的提示生成文本。"""
|
|
|
- raise NotImplementedError("子类必须实现这个方法")
|
|
|
+```python
|
|
|
+# 将所有工具函数放入一个字典,方便后续调用
|
|
|
+available_tools = {
|
|
|
+ "get_weather": get_weather,
|
|
|
+ "get_attraction": get_attraction,
|
|
|
+}
|
|
|
```
|
|
|
|
|
|
-接下来,我们继承 `BaseLLM` 接口,创建一个具体的、可以和任何兼容 `OpenAI` 接口的服务进行通信的客户端。
|
|
|
|
|
|
-这个类主要负责以下三项任务:
|
|
|
|
|
|
-1. <strong>初始化 (`init`)</strong> : 实例化时,接收API密钥、服务地址和模型名称作为参数,并使用这些信息配置底层的 `openai` 客户端。
|
|
|
-2. <strong>生成文本 (`generate`)</strong> : 封装了调用LLM的核心逻辑。它接收一个提示(prompt),构建符合API规范的消息结构,发送请求,然后解析并返回模型生成的文本。
|
|
|
-3. <strong>错误处理</strong>: 使用 `try...except` 结构来捕获执行过程中可能出现的网络或API异常,以增强程序的鲁棒性。
|
|
|
+### 1.3.2 接入大语言模型
|
|
|
|
|
|
-```Python
|
|
|
+当前,许多LLM服务提供商(包括OpenAI、Azure、以及众多开源模型服务框架如Ollama、vLLM等)都遵循了与OpenAI API相似的接口规范。这种标准化为开发者带来了极大的便利。智能体的自主决策能力来源于LLM。我们将实现一个通用的客户端 `OpenAICompatibleClient`,它可以连接到任何兼容OpenAI接口规范的LLM服务。
|
|
|
+
|
|
|
+```python
|
|
|
from openai import OpenAI
|
|
|
|
|
|
-class OpenAICompatibleClient(BaseLLM):
|
|
|
+class OpenAICompatibleClient:
|
|
|
"""
|
|
|
- 用于调用任何兼容OpenAI接口的服务的具体实现类。
|
|
|
+ 一个用于调用任何兼容OpenAI接口的LLM服务的客户端。
|
|
|
"""
|
|
|
- def __init__(self, api_key: str, base_url: str, model: str):
|
|
|
- # 初始化 OpenAI 客户端,指向目标服务地址
|
|
|
- self.client = OpenAI(api_key=api_key, base_url=base_url)
|
|
|
+ def __init__(self, model: str, api_key: str, base_url: str):
|
|
|
self.model = model
|
|
|
+ self.client = OpenAI(api_key=api_key, base_url=base_url)
|
|
|
|
|
|
- def generate(self, prompt: str) -> str:
|
|
|
- """
|
|
|
- 调用兼容OpenAI的API来处理信息。
|
|
|
- """
|
|
|
- print(f"🧠 正在调用 {self.model} 模型...")
|
|
|
-
|
|
|
+ def generate(self, prompt: str, system_prompt: str) -> str:
|
|
|
+ """调用LLM API来生成回应。"""
|
|
|
+ print("正在调用大语言模型...")
|
|
|
try:
|
|
|
- # 构建请求的消息体
|
|
|
messages = [
|
|
|
- {'role': 'system', 'content': 'You are a helpful assistant.'},
|
|
|
+ {'role': 'system', 'content': system_prompt},
|
|
|
{'role': 'user', 'content': prompt}
|
|
|
]
|
|
|
-
|
|
|
- # 发起请求, 注意 stream=False 以便一次性获取完整回答
|
|
|
response = self.client.chat.completions.create(
|
|
|
model=self.model,
|
|
|
messages=messages,
|
|
|
- stream=False
|
|
|
+ stream=False
|
|
|
)
|
|
|
-
|
|
|
- # 提取并返回模型的回答
|
|
|
answer = response.choices[0].message.content
|
|
|
- print("✅ 大语言模型响应成功。")
|
|
|
+ print("大语言模型响应成功。")
|
|
|
return answer
|
|
|
-
|
|
|
except Exception as e:
|
|
|
- print(f"❌ 调用LLM API时发生错误: {e}")
|
|
|
- return "抱歉,调用语言模型服务时出错。"
|
|
|
+ print(f"调用LLM API时发生错误: {e}")
|
|
|
+ return "错误:调用语言模型服务时出错。"
|
|
|
```
|
|
|
|
|
|
-仅有语言能力不足以完成任务,智能体需要通过调用外部工具与环境进行交互。在本例中,行动即执行网络搜索。我们为此编写一个专用的函数。
|
|
|
+要实例化此类,您需要提供三个信息:`API_KEY`、`BASE_URL` 和 `MODEL_ID`,具体值取决于您使用的服务商(如OpenAI官方、Azure、或Ollama等本地模型),如果暂时没有渠道获取,可以参考Datawhale另一本教程的[1.2 API设置](https://datawhalechina.github.io/handy-multi-agent/#/chapter1/1.2.api-setup)。
|
|
|
|
|
|
-`search_web` 函数的逻辑如下:
|
|
|
+### 1.3.3 执行行动循环
|
|
|
|
|
|
-1. 接收一个查询字符串(query)作为参数。
|
|
|
-2. 通过 `ddgs` 库向DuckDuckGo搜索引擎发起查询。
|
|
|
-3. 通过 `region='cn-zh'` 参数,建议搜索引擎返回与中文区域更相关的结果。
|
|
|
-4. 解析返回结果,提取每条内容的文本摘要(snippet),并将其组织成一个列表返回。
|
|
|
+下面的主循环将整合所有组件,并通过格式化后的Prompt驱动LLM进行决策。
|
|
|
|
|
|
-```Python
|
|
|
-from ddgs import DDGS
|
|
|
+```python
|
|
|
+import re
|
|
|
|
|
|
-def search_web(query: str, max_results: int = 5):
|
|
|
- """
|
|
|
- 执行行动 (Action): 调用搜索引擎API来检索信息。
|
|
|
- """
|
|
|
- print(f"🤖 智能体正在使用关键词搜索: '{query}'...")
|
|
|
- try:
|
|
|
- # 使用 with 语句确保资源被正确管理
|
|
|
- with DDGS() as ddgs:
|
|
|
- # 添加 region='cn-zh' 参数以获取更相关的中文搜索结果
|
|
|
- results = [r['body'] for r in ddgs.text(query, region='cn-zh', max_results=max_results)]
|
|
|
- print(f"✅ 搜索完成,找到 {len(results)} 条相关信息。")
|
|
|
- return results
|
|
|
- except Exception as e:
|
|
|
- print(f"❌ 搜索时发生错误: {e}")
|
|
|
- return []
|
|
|
-```
|
|
|
+# --- 1. 配置LLM客户端 ---
|
|
|
+# 请根据您使用的服务,将这里替换成对应的凭证和地址
|
|
|
+API_KEY = "YOUR_API_KEY"
|
|
|
+BASE_URL = "YOUR_BASE_URL"
|
|
|
+MODEL_ID = "YOUR_MODEL_ID"
|
|
|
+TAVILY_API_KEY="YOUR_Tavily_KEY"
|
|
|
+os.environ['TAVILY_API_KEY'] = "YOUR_TAVILY_API_KEY"
|
|
|
|
|
|
-在定义了语言处理核心与外部工具之后,我们需要将它们整合,构建智能体的核心控制流。函数 `information_retrieval_agent` 扮演了主控流程的角色,负责协调各个模块。该流程遵循了经典的“思考-行动-观察”循环,这也是许多智能体系统的核心工作范式。
|
|
|
+llm = OpenAICompatibleClient(
|
|
|
+ model=MODEL_ID,
|
|
|
+ api_key=API_KEY,
|
|
|
+ base_url=BASE_URL
|
|
|
+)
|
|
|
|
|
|
-```Python
|
|
|
-def information_retrieval_agent(user_question: str, llm_client: BaseLLM):
|
|
|
- """
|
|
|
- 网络信息检索智能体的完整工作流程。
|
|
|
- """
|
|
|
- print(f"\n🚀 开始处理新任务: '{user_question}'")
|
|
|
-
|
|
|
- # 1. 思考 (Thought): 查询重写/关键词提取
|
|
|
- keyword_extraction_prompt = f"""
|
|
|
- 请从以下用户问题中,提取出最核心的、适合用于搜索引擎查询的关键词。
|
|
|
- 请只返回关键词,用空格隔开,不要添加任何解释或标点符号。
|
|
|
+# --- 2. 初始化 ---
|
|
|
+user_prompt = "你好,请帮我查询一下今天北京的天气,然后根据天气推荐一个合适的旅游景点。"
|
|
|
+prompt_history = [f"用户请求: {user_prompt}"]
|
|
|
+
|
|
|
+print(f"用户输入: {user_prompt}\n" + "="*40)
|
|
|
|
|
|
- 用户问题: "{user_question}"
|
|
|
+# --- 3. 运行主循环 ---
|
|
|
+for i in range(5): # 设置最大循环次数
|
|
|
+ print(f"--- 循环 {i+1} ---\n")
|
|
|
|
|
|
- 关键词:
|
|
|
- """
|
|
|
- print("📝 正在进行查询重写,提取核心关键词...")
|
|
|
- search_keywords = llm_client.generate(keyword_extraction_prompt).strip()
|
|
|
+ # 3.1. 构建Prompt
|
|
|
+ full_prompt = "\n".join(prompt_history)
|
|
|
|
|
|
- # 2. 行动 (Action): 执行网络搜索
|
|
|
- search_results = search_web(search_keywords)
|
|
|
+ # 3.2. 调用LLM进行思考
|
|
|
+ llm_output = llm.generate(full_prompt, system_prompt=AGENT_SYSTEM_PROMPT)
|
|
|
+ print(f"模型输出:\n{llm_output}\n")
|
|
|
+ prompt_history.append(llm_output)
|
|
|
|
|
|
- if not search_results:
|
|
|
- print("⏹️ 未找到任何信息,任务终止。")
|
|
|
- return
|
|
|
-
|
|
|
- # 3. 观察 (Observation) 与再次思考 (整合)
|
|
|
- integration_prompt = f"""
|
|
|
- 你是一个信息整合助手。请根据下面提供的网络搜索结果,回答用户的原始问题。
|
|
|
- 请注意:
|
|
|
- 1. 你的回答必须完全基于以下提供的“搜索结果”,不能使用你自己的知识。
|
|
|
- 2. 如果搜索结果无法回答问题,请直接说明“根据现有信息,无法回答该问题”。
|
|
|
- 3. 将信息整合成一个流畅、连贯的段落。
|
|
|
-
|
|
|
- ---
|
|
|
- 原始问题: "{user_question}"
|
|
|
- ---
|
|
|
- 搜索结果:
|
|
|
- - {"\n- ".join(search_results)}
|
|
|
- ---
|
|
|
- 你的回答:
|
|
|
- """
|
|
|
- print("🧐 正在整合搜索结果并生成最终答案...")
|
|
|
- final_answer = llm_client.generate(integration_prompt)
|
|
|
-
|
|
|
- # 4. 输出最终结果
|
|
|
- print("\n" + "="*20 + " 最终答案 " + "="*20)
|
|
|
- print(final_answer)
|
|
|
- print("="*50)
|
|
|
-```
|
|
|
-
|
|
|
-最后,程序的入口部分需要进行以下处理:
|
|
|
+ # 3.3. 解析并执行行动
|
|
|
+ action_match = re.search(r"Action: (.*)", llm_output, re.DOTALL)
|
|
|
+ if not action_match:
|
|
|
+ print("解析错误:模型输出中未找到 Action。")
|
|
|
+ break
|
|
|
+ action_str = action_match.group(1).strip()
|
|
|
|
|
|
-1. <strong>配置</strong>: 定义与LLM API通信所需的凭证,如API密钥、服务URL和模型标识符。
|
|
|
-2. <strong>实例化</strong>: 根据配置信息,创建 `OpenAICompatibleClient` 的实例。
|
|
|
-3. <strong>启动</strong>: 调用 `information_retrieval_agent` 函数,传入一个示例问题以演示智能体的工作流程。
|
|
|
-4. <strong>交互</strong>: 提供一个命令行输入接口,允许用户提交自定义问题,与智能体进行交互。
|
|
|
-
|
|
|
-```Python
|
|
|
-if __name__ == "__main__":
|
|
|
- # --- 模型服务配置 ---
|
|
|
- # 请根据你使用的服务商,将这里替换成对应的凭证和地址
|
|
|
- API_KEY = "YOUR-API-KEY"
|
|
|
- BASE_URL = "YOUR-URL"
|
|
|
- MODEL_ID = "YOUR-MODEL"
|
|
|
-
|
|
|
- # 初始化我们想要使用的LLM客户端
|
|
|
- llm = OpenAICompatibleClient(api_key=API_KEY, base_url=BASE_URL, model=MODEL_ID)
|
|
|
+ if action_str.startswith("finish"):
|
|
|
+ final_answer = re.search(r'finish\(answer="(.*)"\)', action_str).group(1)
|
|
|
+ print(f"任务完成,最终答案: {final_answer}")
|
|
|
+ break
|
|
|
|
|
|
- # 演示如何使用这个智能体
|
|
|
- question = "什么是多智能体系统(Multi-Agent System)?它有哪些关键特征?"
|
|
|
- information_retrieval_agent(question, llm_client=llm)
|
|
|
-
|
|
|
- # 允许用户输入自己的问题
|
|
|
- try:
|
|
|
- custom_question = input("\n> 请输入你的问题 (或直接按回车退出): ")
|
|
|
- if custom_question:
|
|
|
- information_retrieval_agent(custom_question, llm_client=llm)
|
|
|
- except KeyboardInterrupt:
|
|
|
- print("\n程序已退出。")
|
|
|
-
|
|
|
->>>
|
|
|
-🚀 开始处理新任务: '什么是多智能体系统(Multi-Agent System)?它有哪些关键特征?'
|
|
|
-📝 正在进行查询重写,提取核心关键词...
|
|
|
-🧠 正在调用 XXX 模型...
|
|
|
-✅ 大语言模型响应成功。
|
|
|
-🤖 智能体正在使用关键词搜索: '多智能体系统 Multi-Agent System 关键特征'...
|
|
|
-✅ 搜索完成,找到 5 条相关信息。
|
|
|
-🧐 正在整合搜索结果并生成最终答案...
|
|
|
-🧠 正在调用 XXX 模型...
|
|
|
-✅ 大语言模型响应成功。
|
|
|
-
|
|
|
-==================== 最终答案 ====================
|
|
|
-一个多智能体系统(Multi-Agent System,缩写为MAS),是由多个智能体组成的一个计算系统,这些智能体在一个共享环境中相互作用、通信、协作或竞争,以完成特定的任务或解决问题。这一概
|
|
|
-念自20世纪70年代起逐渐发展,成为一种重要的分布式计算技术和复杂系统分析与模拟的方法。多智能体系统不仅在计算机科学和人工智能领域发挥着重要作用,还在解决分离的智能体和单层系统
|
|
|
-难以处理的复杂问题上展现出显著优势。通过多个智能体之间的协作与协调,多智能体系统能够提升整体性能和鲁棒性。
|
|
|
-==================================================
|
|
|
-```
|
|
|
-
|
|
|
-至此,一个功能完整的网络信息检索智能体就构建完成了。
|
|
|
-
|
|
|
-### 1.2.5 智能体应用的协作模式
|
|
|
-
|
|
|
-上一节,我们通过亲手构建一个智能体,深入理解了其内部的运作循环。不过在更广泛的应用场景中,我们的角色正越来越多地转变为使用者与协作者。基于智能体在任务中的角色和自主性程度,其协作模式主要分为两种:一种是作为高效工具,深度融入我们的工作流;另一种则是作为自主的协作者,与其他智能体协作完成复杂目标。
|
|
|
-
|
|
|
-本节将探讨这两种交互模式,通过具体案例,展示我们如何与LLM的智能体的构建者”,转变为其“用户”、“伙伴”乃至“管理者”。
|
|
|
-
|
|
|
-<strong>(1)作为开发者工具的智能体</strong>
|
|
|
-
|
|
|
-在这种模式下,智能体被深度集成到开发者的工作流中,作为一种强大的辅助工具。它增强而非取代开发者的角色,通过自动化处理繁琐、重复的任务,让开发者能更专注于创造性的核心工作。这种人机协同的方式,极大地提升了软件开发的效率与质量。
|
|
|
-
|
|
|
-目前,市场上涌现了多款优秀的AI编程辅助工具,它们虽然均能提升开发效率,但在实现路径和功能侧重上各有千秋:
|
|
|
-
|
|
|
-- <strong>GitHubCopilot</strong>: 作为该领域最具影响力的产品之一,Copilot 由 GitHub 与 OpenAI 联合开发。它深度集成于 Visual Studio Code等主流编辑器中,以其强大的代码自动补全能力而闻名。开发者在编写代码时,Copilot 能实时提供整行甚至整个函数块的建议。近年来,它也通过 Copilot Chat 扩展了对话式编程的能力,允许开发者在编辑器内通过聊天解决编程问题。
|
|
|
-- <strong>Claude Code</strong>: Claude Code 是由 Anthropic 开发的 AI 编程助手,旨在通过自然语言指令帮助开发者在终端中高效地完成编码任务。它能够理解完整的代码库结构,执行代码编辑、测试和调试等操作,支持从描述功能到代码实现的全流程开发。Claude Code 还提供了无交互(headless)模式,适用于 CI、pre-commit hooks、构建脚本和其他自动化场景,为开发者提供了强大的命令行编程体验。
|
|
|
-- <strong>Trae</strong>: 作为新兴的 AI 编程工具,Trae 专注于为开发者提供智能化的代码生成和优化服务。它通过深度学习技术分析代码模式,能够为开发者提供精准的代码建议和自动化重构方案。Trae 的特色在于其轻量级的设计和快速响应能力,特别适合需要频繁迭代和快速原型开发的场景。
|
|
|
-- <strong>Cursor</strong>: 与上述主要作为插件或集成功能存在的工具不同,Cursor 则选择了一条更具整合性的路径,它本身就是一个AI原生的代码编辑器。它并非在现有编辑器上增加AI功能,而是在设计之初就将AI交互作为核心。除了具备顶级的代码生成和聊天能力外,它更强调让AI理解整个代码库的上下文,从而实现更深层次的问答、重构和调试。
|
|
|
-
|
|
|
-当然还有许多优秀的工具没有例举,为了更具体地展示此类工具如何与开发者进行日常协同,我们将选择 Cursor 作为使用案例。因为它编辑器即智能体的设计理念,能完整地体现AI作为开发者工具的交互模式。下面,我们将通过几个常见的开发场景,展示如何与Cursor这样的工具型智能体进行协作。
|
|
|
-
|
|
|
-<strong>场景一:快速生成代码,从零到一创建一个“贪吃蛇”游戏。</strong>
|
|
|
+ tool_name = re.search(r"(\w+)\(", action_str).group(1)
|
|
|
+ args_str = re.search(r"\((.*)\)", action_str).group(1)
|
|
|
+ kwargs = dict(re.findall(r'(\w+)="([^"]*)"', args_str))
|
|
|
|
|
|
-本场景将演示如何利用 Cursor 从一个完全空白的项目开始,通过一次综合性的自然语言指令,生成一个包含多个文件的完整网页应用。我们的目标是创建一个经典的“贪吃蛇”游戏,以此展示 AI 在项目启动阶段快速生成原型代码的能力。
|
|
|
+ if tool_name in available_tools:
|
|
|
+ observation = available_tools[tool_name](**kwargs)
|
|
|
+ else:
|
|
|
+ observation = f"错误:未定义的工具 '{tool_name}'"
|
|
|
|
|
|
-整个操作流程非常高效。首先,在 Cursor 编辑器中创建一个空项目,并预先建立三个核心文件:`index.html` 用于定义网页结构,`style.css` 用于控制界面样式,`script.js` 用于实现游戏逻辑。这一步是为了给 AI 提供一个明确的操作目标和上下文环境。
|
|
|
-
|
|
|
-接下来是关键的指令下达环节。在聊天侧边栏中,我们首先使用 `@` 符号将这三个文件全部引用,确保 AI 能够理解这是一个多文件协作的项目。随后,我们输入一段详细描述需求的指令,将任务清晰地分配给每个文件:
|
|
|
-
|
|
|
-```Plain
|
|
|
-# Prompt
|
|
|
-@index.html @style.css @script.js
|
|
|
-你好,请帮我创建一个经典版的“贪吃蛇”网页游戏。
|
|
|
-在 index.html 中,设置好基本的HTML结构,包含一个游戏画布(canvas)和一个显示分数的元素。
|
|
|
-在 style.css 中,为游戏界面添加一些简单的样式,比如让画布居中,设置一个深色的背景。
|
|
|
-在 script.js 中,实现游戏的全部逻辑: 绘制游戏区域、蛇和食物。 通过键盘的上下左右箭头控制蛇的移动方向。 实现蛇吃到食物后身体变长、分数增加的逻辑。 处理游戏结束的条件(撞到墙壁或自己)。 包含一个重新开始游戏的功能。
|
|
|
+ # 3.4. 记录观察结果
|
|
|
+ observation_str = f"Observation: {observation}"
|
|
|
+ print(f"{observation_str}\n" + "="*40)
|
|
|
+ prompt_history.append(observation_str)
|
|
|
```
|
|
|
|
|
|
-Cursor 接收到指令后,会立即分析需求,并同时为这三个文件生成对应的代码。它不会直接覆写文件,而是在聊天窗口中以代码差异的形式,清晰地展示将要应用的全部修改,如图 1.7 所示。这为开发者提供了一个审查和确认的环节。在确认 AI 的方案无误后,只需点击视为接受的按钮,所有代码就会被自动、准确地写入对应的文件中。
|
|
|
+通过以上步骤,我们构建了一个完整的、由真实LLM驱动的智能体。其核心在于“工具”和“提示工程”的结合,这正是当前主流智能体框架(如LangChain、LlamaIndex等)的设计精髓。
|
|
|
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-8.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.7 Cursor界面展示了AI为三个文件生成的代码</p>
|
|
|
-</div>
|
|
|
+### 1.3.4 运行案例分析
|
|
|
|
|
|
-最终,我们得到了一个功能完备、可直接在浏览器中运行的“贪吃蛇”游戏,如图 1.8 所示。这个过程将传统开发中需要数小时的手动编码工作,压缩为一次与 AI 的自然语言交互,极大地提升了从概念到可运行原型的开发效率。
|
|
|
+以下输出完整地展示了一个成功的智能体执行流程。通过对这个三轮循环的分析,我们可以清晰地看到智能体解决问题的核心能力。
|
|
|
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-9.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.8 贪吃蛇游戏运行界面</p>
|
|
|
-</div>
|
|
|
+```bash
|
|
|
+用户输入: 你好,请帮我查询一下今天北京的天气,然后根据天气推荐一个合适的旅游景点。
|
|
|
+========================================
|
|
|
+--- 循环 1 ---
|
|
|
|
|
|
-<strong>场景二:理解与重构现有代码,优化一个复杂的函数。</strong>
|
|
|
-
|
|
|
-软件开发不仅仅是创造新功能,更多的时候是在维护和优化已有的代码。随着项目迭代,我们经常会遇到一些“代码坏味道”,其中最常见的就是逻辑臃肿、职责不清的全能函数。本场景将演示如何利用 Cursor,将一个难以维护的复杂函数,优雅地重构为清晰、模块化的代码。
|
|
|
-
|
|
|
-假设我们在一个电商项目的代码库中,遇到了一个名为 `processOrder` 的函数。这个函数最初可能很简单,但随着业务逻辑的增加(如添加优惠券、模拟支付、更新库存等),它逐渐膨胀到上百行,将订单处理的所有步骤都混合在一起。
|
|
|
-
|
|
|
-这样的函数存在明显的问题:
|
|
|
-
|
|
|
-- <strong>难以阅读:</strong> 任何开发者想理解完整的订单流程,都必须从头到尾阅读整个函数。
|
|
|
-- <strong>难以修改:</strong> 如果只想修改库存更新的逻辑,也必须小心翼翼地在庞大的函数体中寻找目标代码,稍有不慎就可能影响到支付或验证等其他环节。
|
|
|
-- <strong>难以测试:</strong> 无法对验证、计价、支付等子任务进行独立的单元测试。
|
|
|
-
|
|
|
-以下是这个函数的原始代码 (order.js),它是一个典型的需要重构的对象:
|
|
|
-
|
|
|
-```JavaScript
|
|
|
-// 一个难以维护的函数
|
|
|
-function processOrder(order) {
|
|
|
- // 步骤1: 验证订单数据
|
|
|
- if (!order.id || !order.items || order.items.length === 0) {
|
|
|
- console.error("订单数据无效");
|
|
|
- return;
|
|
|
- }
|
|
|
-
|
|
|
- // 步骤2: 计算总价
|
|
|
- let total = 0;
|
|
|
- for (const item of order.items) {
|
|
|
- total += item.price * item.quantity;
|
|
|
- }
|
|
|
- if (order.coupon) {
|
|
|
- // 优惠券逻辑
|
|
|
- if (order.coupon === "SAVE10") {
|
|
|
- total *= 0.9;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- // 步骤3: 调用支付API
|
|
|
- console.log(`正在为订单 ${order.id} 调用支付接口,金额: ${total.toFixed(2)}`);
|
|
|
- const paymentSuccess = Math.random() > 0.1; // 模拟支付成功或失败
|
|
|
- if (!paymentSuccess) {
|
|
|
- console.error("支付失败");
|
|
|
- return;
|
|
|
- }
|
|
|
-
|
|
|
- // 步骤4: 更新库存
|
|
|
- for (const item of order.items) {
|
|
|
- console.log(`正在更新商品 ${item.productId} 的库存...`);
|
|
|
- }
|
|
|
-
|
|
|
- // 步骤5: 发送确认邮件
|
|
|
- console.log(`正在向用户 ${order.userId} 发送订单确认邮件...`);
|
|
|
-
|
|
|
- console.log("订单处理完成!");
|
|
|
-}
|
|
|
-```
|
|
|
-
|
|
|
-面对这样的函数,传统的手动重构既耗时又容易出错。但在 Cursor 中,这个过程可以被简化为一次与 AI 的对话。首先,在编辑器中选中整个 `processOrder` 函数体。然后,在选中的代码上方激活内联聊天框。在这里,我们输入一条重构指令:
|
|
|
-
|
|
|
-```Plain
|
|
|
-# Prompt
|
|
|
-
|
|
|
-“请将这个函数重构。把验证、计算总价、处理支付、更新库存和发送邮件这几个步骤,分别拆分成独立的、职责单一的私有函数。同时为每个新函数添加清晰的JSDoc注释。”
|
|
|
-```
|
|
|
-
|
|
|
-Cursor 的 AI 会立刻理解你的意图,分析函数内部的逻辑块,并生成重构方案。它不会直接修改你的代码,而是提供一个清晰的差异对比预览。如图1.9所示,你可以清楚地看到哪些代码被移除(红色),哪些是新增的(绿色),确保所有改动都在你的掌控之中。
|
|
|
+正在调用大语言模型...
|
|
|
+大语言模型响应成功。
|
|
|
+模型输出:
|
|
|
+Thought: 首先需要获取北京今天的天气情况,之后再根据天气情况来推荐旅游景点。
|
|
|
+Action: get_weather(city="北京")
|
|
|
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-10.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.9 Cursor界面展示函数代码重构过程</p>
|
|
|
-</div>
|
|
|
+Observation: 北京当前天气:Sunny,气温26摄氏度
|
|
|
+========================================
|
|
|
+--- 循环 2 ---
|
|
|
|
|
|
-确认方案后,点击确认接受的按钮,重构便即刻完成。原来的函数被一个清晰的主流程函数和多个职责单一的辅助函数所取代。最终,我们没有手动修改一行代码。通过一条自然语言指令,一个臃肿的函数就被重构了。重构后的 `processOrder` 函数本身变得极为简洁,其代码几乎就像是业务流程的伪代码,清晰地描述了处理订单的每一个步骤。而每个具体的步骤则被封装在独立的、命名清晰的私有函数中,它们易于理解、易于独立测试,也更易于未来的维护和扩展。这充分展示了 AI 在代码理解和重构方面的强大能力,使其成为提升现有代码库质量的得力助手。
|
|
|
+正在调用大语言模型...
|
|
|
+大语言模型响应成功。
|
|
|
+模型输出:
|
|
|
+Thought: 现在已经知道了北京今天的天气是晴朗且温度适中,接下来可以基于这个信息来推荐一个适合的旅游景点了。
|
|
|
+Action: get_attraction(city="北京", weather="Sunny")
|
|
|
|
|
|
-<strong>场景三:辅助调试,快速定位并修复运行时错误。</strong>
|
|
|
+Observation: 北京在晴天最值得去的旅游景点是颐和园,因其美丽的湖景和古建筑。另一个推荐是长城,因其壮观的景观和历史意义。
|
|
|
+========================================
|
|
|
+--- 循环 3 ---
|
|
|
|
|
|
-调试是软件开发中不可或缺的一环,但有时排查一个看似简单的运行时错误也可能耗费大量时间。本场景将展示当程序抛出错误时,如何利用 Cursor 快速理解错误原因、定位问题,并获得高质量的修复方案,从而显著提高调试效率。
|
|
|
+正在调用大语言模型...
|
|
|
+大语言模型响应成功。
|
|
|
+模型输出:
|
|
|
+Thought: 已经获得了两个适合晴天游览的景点建议,现在可以根据这些信息给用户提供满意的答复。
|
|
|
+Action: finish(answer="今天北京的天气是晴朗的,气温26摄氏度,非常适合外出游玩。我推荐您去颐和园欣赏美丽的湖景和古建筑,或者前往长城体验其壮观的景观和深厚的历史意义。希望您有一个愉快的旅行!
|
|
|
+")
|
|
|
|
|
|
-假设我们正在开发一个简单的用户信息展示功能。代码逻辑很简单:获取一个 DOM 元素,然后将用户信息填充进去。然而,在浏览器中运行时,程序并未如期执行,反而在控制台抛出了一个常见的 `TypeError`。下面是存在问题的代码 (app.js):
|
|
|
-
|
|
|
-```JavaScript
|
|
|
-function displayUserGreeting(user) {
|
|
|
- // 尝试获取ID为 'greeting' 的元素
|
|
|
- const greetingElement = document.getElementById('greeting');
|
|
|
-
|
|
|
- // 如果用户存在,就显示欢迎信息
|
|
|
- if (user) {
|
|
|
- greetingElement.textContent = `你好, ${user.name}!`;
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-// 模拟获取用户信息
|
|
|
-const currentUser = { name: "Alice" };
|
|
|
-displayUserGreeting(currentUser);
|
|
|
+任务完成,最终答案: 今天北京的天气是晴朗的,气温26摄氏度,非常适合外出游玩。我推荐您去颐和园欣赏美丽的湖景和古建筑,或者前往长城体验其壮观的景观和深厚的历史意义。希望您有一个愉快的旅行!
|
|
|
```
|
|
|
|
|
|
-在浏览器开发者工具的控制台中,我们看到了如下截图所示的错误信息,它明确指出了错误类型和发生位置:
|
|
|
+这个简单的旅行助手案例,集中演示了基于`Thought-Action-Observation`范式的智能体所具备的四项基本能力:任务分解、工具调用、上下文理解和结果合成。正是通过这个循环的不断迭代,智能体才得以将一个模糊的用户意图,转化为一系列具体、可执行的步骤,并最终达成目标。
|
|
|
|
|
|
-```JavaScript
|
|
|
-Uncaught TypeError: Cannot set properties of null (setting 'textContent')
|
|
|
-```
|
|
|
+## 1.4 智能体应用的协作模式
|
|
|
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-11.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.10 Cursor开发程序报错提示</p>
|
|
|
-</div>
|
|
|
+上一节,我们通过亲手构建一个智能体,深入理解了其内部的运作循环。不过在更广泛的应用场景中,我们的角色正越来越多地转变为使用者与协作者。基于智能体在任务中的角色和自主性程度,其协作模式主要分为两种:一种是作为高效工具,深度融入我们的工作流;另一种则是作为自主的协作者,与其他智能体协作完成复杂目标。
|
|
|
|
|
|
-如图1.10所示,程序试图为一个值为 `null` 的东西设置 `textContent` 属性,这在 JavaScript 中是不允许的。Cursor 提供了一种更直接的调试方式。我们只需将控制台的完整错误信息复制到剪贴板,然后在 Cursor 的聊天侧边栏中,`@` 引用相关的代码文件并发起提问:
|
|
|
+### 1.4.1 作为开发者工具的智能体
|
|
|
|
|
|
-```JavaScript
|
|
|
-# prompt
|
|
|
-@app.js 我的程序报了下面这个错误,请帮我分析一下原因,并告诉我如何修复它。 Uncaught TypeError: Cannot set properties of null (setting 'textContent')
|
|
|
-```
|
|
|
+在这种模式下,智能体被深度集成到开发者的工作流中,作为一种强大的辅助工具。它增强而非取代开发者的角色,通过自动化处理繁琐、重复的任务,让开发者能更专注于创造性的核心工作。这种人机协同的方式,极大地提升了软件开发的效率与质量。
|
|
|
|
|
|
-Cursor 会结合错误信息和 `app.js` 的源代码进行综合分析,迅速给出诊断和解决方案。它不仅会解释发生了什么,还会深入说明为什么会发生,并提供一段可以直接应用的、更健壮的代码。
|
|
|
+目前,市场上涌现了多款优秀的AI编程辅助工具,它们虽然均能提升开发效率,但在实现路径和功能侧重上各有千秋:
|
|
|
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-12.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.11 Cursor开发程序报错提示</p>
|
|
|
-</div>
|
|
|
+- <strong>GitHubCopilot</strong>: 作为该领域最具影响力的产品之一,Copilot 由 GitHub 与 OpenAI 联合开发。它深度集成于 Visual Studio Code等主流编辑器中,以其强大的代码自动补全能力而闻名。开发者在编写代码时,Copilot 能实时提供整行甚至整个函数块的建议。近年来,它也通过 Copilot Chat 扩展了对话式编程的能力,允许开发者在编辑器内通过聊天解决编程问题。
|
|
|
+- <strong>Claude Code</strong>: Claude Code 是由 Anthropic 开发的 AI 编程助手,旨在通过自然语言指令帮助开发者在终端中高效地完成编码任务。它能够理解完整的代码库结构,执行代码编辑、测试和调试等操作,支持从描述功能到代码实现的全流程开发。Claude Code 还提供了无交互(headless)模式,适用于 CI、pre-commit hooks、构建脚本和其他自动化场景,为开发者提供了强大的命令行编程体验。
|
|
|
+- <strong>Trae</strong>: 作为新兴的 AI 编程工具,Trae 专注于为开发者提供智能化的代码生成和优化服务。它通过深度学习技术分析代码模式,能够为开发者提供精准的代码建议和自动化重构方案。Trae 的特色在于其轻量级的设计和快速响应能力,特别适合需要频繁迭代和快速原型开发的场景。
|
|
|
+- <strong>Cursor</strong>: 与上述主要作为插件或集成功能存在的工具不同,Cursor 则选择了一条更具整合性的路径,它本身就是一个AI原生的代码编辑器。它并非在现有编辑器上增加AI功能,而是在设计之初就将AI交互作为核心。除了具备顶级的代码生成和聊天能力外,它更强调让AI理解整个代码库的上下文,从而实现更深层次的问答、重构和调试。
|
|
|
|
|
|
-如图1.11所示,通过一次简单的“复制-粘贴-提问”,我们完成了传统调试中多个步骤才能完成的工作。我们不仅立刻明白了错误的根本原因(HTML 结构与 JavaScript 脚本不匹配),还直接获得了一段经过优化的修复代码。这段新代码通过增加一个前置检查,提高了程序的容错性,能够有效避免未来同类错误的发生。
|
|
|
+当然还有许多优秀的工具没有例举,不过它们共同指向了一个明确的趋势:AI 正在深度融入软件开发的全生命周期,通过构建高效的人机协同工作流,深刻地重塑着软件工程的效率边界与开发范式。
|
|
|
|
|
|
-<strong>(2)作为自主协作者的智能体</strong>
|
|
|
+### 1.4.2 作为自主协作者的智能体
|
|
|
|
|
|
与作为工具辅助人类不同,第二种交互模式将智能体的自动化程度提升到了一个全新的层次,自主协作者。在这种模式下,我们不再是手把手地指导AI完成每一步,而是将一个高层级的目标委托给它。智能体会像一个真正的项目成员一样,独立地进行规划、推理、执行和反思,直到最终交付成果。这种从助手到协作者的转变,使得LLM智能体更深的进入了大众的视野。它标志着我们与AI的关系从“命令-执行”演变为“目标-委托”。智能体不再是被动的工具,而是主动的目标追求者。
|
|
|
|
|
|
-当前,实现这种自主协作的思路百花齐放,涌现了大量优秀的框架和产品,如BabyAGI、AutoGPT、CrewAI、AutoGen等。它们虽然在具体实现上各有侧重,但其核心思想都是赋予AI更大程度的自主权。为了清晰地展示这一领域的关键思想脉络,我们将选取三个具有里程碑意义的案例进行介绍。它们分别代表了三种截然不同的架构范式:
|
|
|
-
|
|
|
-1. <strong>AgentGPT</strong>:它是一个典型的单智能体、递归循环的范例。其核心在于一个强大的通用智能体通过“思考-规划-行动”的闭环,不断自我提示,以完成一个开放式的高层级目标。
|
|
|
-2. <strong>CAMEL</strong>:它引入了双智能体、角色扮演的协作框架。通过为两个智能体(一个“任务规划者”和一个“任务执行者”)设定明确的角色和沟通协议,让它们在一个结构化的对话中协同完成任务。
|
|
|
-3. <strong>Manus AI</strong>:这是一个多智能体、多模型的集成系统,模拟了一个真实的企业部门或专家团队。它内部包含多个各司其职的专业子智能体(如规划、研究、执行、验证),它们并行协作,共同完成一个复杂的端到端任务。
|
|
|
-
|
|
|
-接下来,我们将通过具体的案例,逐一剖析这三种自主协作模式的技术特点。
|
|
|
-
|
|
|
-<strong>案例一:AgentGPT</strong>
|
|
|
-
|
|
|
-AgentGPT是最早引发大众对自主智能体广泛关注的开源项目之一。其核心机制在于一个强大的通用智能体,通过一个持续的“思考-规划-行动”闭环,不断地自我提示,以完成一个开放式的、高层级的目标。用户仅需提供一个最终目标,智能体便会自主地进行任务分解,然后利用各种工具(如网页搜索、文件读写、代码执行)去逐一完成子任务,并根据执行结果不断反思和调整后续计划。
|
|
|
+当前,实现这种自主协作的思路百花齐放,涌现了大量优秀的框架和产品,从早期的 BabyAGI、AutoGPT,到如今更为成熟的 CrewAI、AutoGen、MetaGPT、LangGraph 等优秀框架,共同推动着这一领域的高速发展。虽然具体实现千差万别,但它们的架构范式大致可以归纳为几个主流方向:
|
|
|
|
|
|
-本场景将深入探讨这个智能体项目。与前面案例中通过单次、详尽指令完成任务的模式不同,AgentGPT的核心魅力在于其自主规划和持续迭代的能力。它模拟了一个拥有独立思考能力的“研究员”,仅需一个高层级的开放式目标,便能自主地启动一个持续的“思考-规划-行动-观察”闭环,直至达成最终目的。我们将通过一个经典的商业研究任务,来具象化AgentGPT是如何像一个不知疲倦的个体主义者一样,独立完成复杂项目的。
|
|
|
+1. <strong>单智能体自主循环</strong>:这是早期的典型范式,如 <strong>AgentGPT</strong> 所代表的模式。其核心是一个通用智能体通过“思考-规划-执行-反思”的闭环,不断进行自我提示和迭代,以完成一个开放式的高层级目标。
|
|
|
+2. <strong>多智能体协作</strong>:这是当前最主流的探索方向,旨在通过模拟人类团队的协作模式来解决复杂问题。它又可细分为不同模式: <strong>角色扮演式对话</strong>:如 <strong>CAMEL</strong> 框架,通过为两个智能体(例如,“程序员”和“产品经理”)设定明确的角色和沟通协议,让它们在一个结构化的对话中协同完成任务。 <strong>组织化工作流</strong>:如 <strong>MetaGPT</strong> 和 <strong>CrewAI</strong>,它们模拟一个分工明确的“虚拟团队”(如软件公司或咨询小组)。每个智能体都有预设的职责和工作流程(SOP),通过层级化或顺序化的方式协作,产出高质量的复杂成果(如完整的代码库或研究报告)。<strong>AutoGen</strong> 和 <strong>AgentScope</strong> 则提供了更灵活的对话模式,允许开发者自定义智能体间的复杂交互网络。
|
|
|
+3. <strong>高级控制流架构</strong>:诸如 <strong>LangGraph</strong> 等框架,则更侧重于为智能体提供更强大的底层工程基础。它将智能体的执行过程建模为状态图(State Graph),从而能更灵活、更可靠地实现循环、分支、回溯以及人工介入等复杂流程。
|
|
|
|
|
|
-假设我们将要在芝加哥市中心开设一家新的精品咖啡店并进行市场分析。项目成员就是AgentGPT。我们不需要为它制定详细的工作计划,只需要向AgentGPT下达一个不包含任何具体步骤的高层级指令。这比起“贪吃蛇”案例中需要明确告知每个文件具体做什么会简洁不少。
|
|
|
+这些不同的架构范式,共同推动着自主智能体从理论构想走向更广泛的实际应用,使其有能力应对日益复杂的真实世界任务。在我们的后续章节中,也会感受不同类型框架之间的差异和优势。
|
|
|
|
|
|
-```Plain
|
|
|
-# Prompt
|
|
|
-目标:为在芝加哥市中心开设一家新的精品咖啡店进行市场分析,并生成一份总结报告。
|
|
|
-```
|
|
|
-
|
|
|
-这句指令就是一次彻底的“委托”。提交之后,人类的角色便从“指挥官”转变为“观察者”。AgentGPT的内部循环被激活,一场自主的探索之旅就此展开。
|
|
|
-
|
|
|
-接收到目标后,AgentGPT并不会立即执行单一动作,而是首先进行一次全面的任务规划。它会将“为精品咖啡店进行市场分析”这个高层级目标,分解成一个详尽的任务列表。正如真实操作界面所示,它会生成一系列具体的子任务,如图1.12所示。
|
|
|
-
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-13.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.12 AgentGPT运行过程</p>
|
|
|
-</div>
|
|
|
-
|
|
|
-
|
|
|
-这个初始计划构成了它的行动蓝图。随后,AgentGPT会从列表的第一个任务开始,自主选择合适的工具(如网页搜索)来执行。这个发现并没有结束,反而成为了下一个行动的催化剂。这展现了AgentGPT作为自主智能体的核心优势:它无需人类提示下一步,便能根据已有信息自主规划并深化研究路径。它会继续这个循环,深挖竞争对手的优劣势、研究本地的消费趋势,并将所有收集到的信息,包括人口数据、竞争列表、消费热点等,自动写入一个文本文件中,作为它的工作笔记。整个过程就像一个不知疲倦的研究员,通过不断的自我对话和自我纠偏来逼近最终目标。当它判断信息足够支撑一份报告时,便会着手整合信息,最终生成一份结构化的分析文档。
|
|
|
-
|
|
|
-AgentGPT的实操过程淋漓尽致地展现了单智能体范式的力量。它拥有极高的自主性,能够将一个模糊的开放式目标,层层分解为具体、可执行的步骤,这在处理探索性任务时效率惊人。然而,这种个体主义的工作模式也并非完美。作为一个通用的思考者,它缺乏特定领域的深度知识。它能找到关于咖啡市场的数据,但它并不真正懂咖啡。因此,它的分析可能广度有余,而深度不足。
|
|
|
-
|
|
|
-更核心的缺陷在于其递归循环的脆弱性。这个不知疲倦的循环也可能使其陷入低效的自证陷阱,在某个不重要的细节上反复搜索,或因为一次错误的解读而导致后续所有步骤跑偏,消耗大量时间和计算资源。由于缺少一个批判者或是合作者的角色来审视其规划,它的策略完全依赖于自身的推理链。一旦最初的思路出现偏差,整个过程便可能走向错误的方向,而无人制止。
|
|
|
-
|
|
|
-总而言之,AgentGPT作为一个单智能体循环项目的典范,证明了“目标-委托”模式的可行性。它像一个能力全面的独立顾问,能独自处理复杂的项目。但它的成功和其固有的单打独斗的局限性,也自然而然地引出了下一个问题:如果一个智能体容易犯错,那么引入另一个智能体进行监督和协作,是否会更有效?这便是我们下一个案例,CAMEL的<strong>角色扮演(Role-Playing)</strong>协作范式。
|
|
|
-
|
|
|
-<strong>案例二:CAMEL</strong>
|
|
|
-
|
|
|
-如果说AgentGPT是一个独自完成所有工作的个体主义者,那么CAMEL框架则探索了截然不同的协作路径。通过精心设计的<strong>初始提示(Inception Prompting)</strong>技术,CAMEL为两个AI智能体分配了不同的角色,一个扮演“任务规划者”(AI User),另一个扮演“任务执行者”(AI Assistant),让它们在一个高度结构化的对话中,通过相互启发和协作来完成任务。这种方案模拟真实世界中专家之间的合作。规划者负责提出想法、需求和高层级的方向,而执行者则负责提供技术方案、实现细节和可行性分析。在一定程度上,它解决了单智能体容易陷入自我逻辑闭环、缺乏外部视角纠偏的问题。
|
|
|
-
|
|
|
-为了体验这种合作模式,我们设定一个需要金融领域知识和编程技术深度结合的任务:为股票市场开发一个交易机器人。在这个场景中,我们不再是向智能体下达一个开放式的目标,而是为其设定好分工明确的角色和初始任务,并观察这场自主的、结构化的设计讨论如何展开。
|
|
|
-
|
|
|
-```Plain
|
|
|
-# Prompt
|
|
|
-初始任务:为股票市场开发一个交易机器人。
|
|
|
+### 1.4.3 Workflow和Agent的差异
|
|
|
|
|
|
-角色分配:
|
|
|
-- AI User (规划者): 股票交易员 (Stock Trader)
|
|
|
-- AI Assistant (执行者): Python 程序员 (Python Programmer)
|
|
|
-```
|
|
|
-
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-14.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.13 CAMEL框架执行任务过程</p>
|
|
|
-</div>
|
|
|
-
|
|
|
-如图1.13所示,这场对话会持续进行下去,遵循“提出方案-确认实现”的节奏,不断深化交易机器人的功能,从风险管理、回测系统,到与其他API的集成。规划者(股票交易员)始终聚焦于交易策略,而执行者(Python程序员)则专注于技术实现。当股票交易员认为机器人的核心功能已经足够完善时,它会发出一个特殊的终止指令`<CAMEL_TASK_DONE>`,整个协作过程便随之结束。最终的产出是一套功能明确的交易机器人原型代码。
|
|
|
-
|
|
|
-CAMEL的协作模式通过角色分工,它有效地避免了单智能体在专业深度上的不足。规划者和执行者各自专注于自己擅长的领域,使得最终方案在交易策略和技术可行性上都得到了保障。然而,这种模式的成功高度依赖于初始角色的设定。如果角色定义不清晰或不恰当,整个对话可能会变得低效甚至无效。此外,但它在处理极其开放、模糊的任务方面可能存在局限。不过总的来说,CAMEL为我们展示了一种通过分工与合作来提升AI能力的有效途径。这自然也引出了更进一步的思考:如果两个智能体的合作就能如此高效,那么一个模拟真实团队、拥有多个不同角色的多智能体系统,又将释放出怎样的潜力呢?Manus AI为我们提供了一种可行途径。
|
|
|
-
|
|
|
-<strong>案例三:Manus AI</strong>
|
|
|
-
|
|
|
-如果说AgentGPT是一个个体工作者,CAMEL是一个两人小组,那么Manus AI则代表了更高层次的组织形式:一个集成的、产品化的虚拟团队。它不再仅仅是一个开源框架或实验性项目,而是一个旨在交付完整、可用最终产品的自主系统。通过编排一个由多个各司职职的专业子智能体(如规划、研究、执行、验证)组成的团队,来处理复杂的端到端任务。用户只需提出一个高层级的需求,Manus AI就能像一个项目团队一样,在云端异步执行所有步骤,并最终交付一个成品,而非仅仅是文本或代码。
|
|
|
+在理解了智能体作为“工具”和“协作者”两种模式后,我们有必要对Workflow和Agent的差异展开讨论,尽管它们都旨在实现任务自动化,但其底层逻辑、核心特征和适用场景却截然不同。
|
|
|
|
|
|
-为了充分展现其团队协作和项目交付能力,我们设定一个比单一网页更复杂的任务:创建一个名为“Pixel Demo”的在线迷你游戏网站。这个任务需要并行开发多个独立的游戏模块,并将其整合到一个统一的门户页面中。
|
|
|
-
|
|
|
-```Plain
|
|
|
-# Prompt
|
|
|
-创建一个名为“Pixel Demo”的在线迷你游戏网站。要求:
|
|
|
-- 风格:复古像素风。
|
|
|
-- 门户页面 (index.html): 包含网站标题和一个用于展示所有游戏的网格布局。
|
|
|
-- 游戏模块:
|
|
|
- 1. 井字棋 (Tic-Tac-Toe)
|
|
|
- 2. 贪吃蛇 (Snake)
|
|
|
-- 交付物:一个包含所有HTML, CSS, 和JavaScript文件的可运行项目压缩包。
|
|
|
-```
|
|
|
+简单来说,<strong>Workflow 是让 AI 按部就班地执行指令,而 Agent 则是赋予 AI 自由度去自主达成目标。</strong>
|
|
|
|
|
|
<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-15.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.14 Manus AI执行任务过程</p>
|
|
|
+ <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-18.png" alt="图片描述" width="90%"/>
|
|
|
+ <p>图 1.6 Workflow和Agent的差异</p>
|
|
|
</div>
|
|
|
|
|
|
-Manus AI接收到任务后,其内部的虚拟团队便开始了高效的协同工作。如图1.14所示,这远比线性的单智能体或双智能体对话要复杂。其内部的规划智能体首先像项目经理一样,将任务分解为清晰的项目蓝图。随后多个执行智能体像开发团队一样并行工作,分别处理门户页面、全局样式和各个独立的游戏模块,在验证智能体进行代码审查和功能测试后,交付智能体最终会将所有文件打包。最终产出的,便是一个可以直接解压部署的完整项目,如图1.15的“PIXEL DEMO”项目实况所示,一个结构完整、功能可用的多页面网站。
|
|
|
-
|
|
|
-<div align="center">
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-16.png" alt="图片描述" width="90%"/>
|
|
|
- <p>图 1.15 PIXEL DEMO项目实况展示</p>
|
|
|
-</div>
|
|
|
-
|
|
|
-Manus AI所代表的多智能体范式,其优势是显然的。它实现了从“生成内容”到“交付产品”的跨越,通过并行化处理,其开发效率远超单智能体或双智能体模式。然而,这种能力的背后是极高的编排复杂性。如何有效地管理和协调多个智能体、处理它们之间的依赖关系仍是一种巨大的技术挑战,并且整个过程对用户来说可能像一个黑箱。
|
|
|
-
|
|
|
-从AgentGPT的单智能体循环,到CAMEL的双智能体协作,再到Manus AI的多智能体交互,我们清晰地看到了自主智能体从简单工具向<strong>代理式人工智能(Agentic AI)</strong>演进的技术脉络。每一种范式都在尝试解决前一种的局限,共同推动着我们与AI协作的边界。
|
|
|
+如图1.6所示,工作流是一种传统的自动化范式,其核心是<strong>对一系列任务或步骤进行预先定义的、结构化的编排</strong>。它本质上是一个精确的、静态的流程图,规定了在何种条件下、以何种顺序执行哪些操作。一个典型的案例:某企业的费用报销审批流程。员工提交报销单(触发)-> 如果金额小于500元,直接由部门经理审批 -> 如果金额大于500元,先由部门经理审批,再流转至财务总监审批 -> 审批通过后,通知财务部打款。整个过程的每一步、每一个判断条件都被精确地预先设定。
|
|
|
|
|
|
-## 1.3 多智能体系统简介
|
|
|
+与工作流不同,基于大型语言模型的智能体是一个<strong>具备自主性的、以目标为导向的系统</strong>。它不仅仅是执行预设指令,而是能够在一定程度上理解环境、进行推理、制定计划,并动态地采取行动以达成最终目标。LLM在其中扮演着“大脑”的角色。一个典型的例子,便是我们在1.3节中写的智能旅行助手。当我们向它下达一个新指令,例如:<strong>“你好,请帮我查询一下今天北京的天气,然后根据天气推荐一个合适的旅游景点。”</strong> 它的处理过程充分展现了其自主性:
|
|
|
|
|
|
-### 1.3.1 从个体到协作
|
|
|
+1. <strong>规划与工具调用:</strong> Agent首先会把任务拆解为两个步骤:① 查询天气;② 基于天气推荐景点。随即,它会自主选择并调用“天气查询API”,并将“北京”作为参数传入。
|
|
|
+2. <strong>推理与决策:</strong> 假设API返回结果为“晴朗,微风”。Agent的LLM大脑会基于这个信息进行推理:“晴天适合户外活动”。接着,它会根据这个判断,在它的知识库或通过搜索引擎这个工具中,筛选出北京的户外景点,如故宫、颐和园、天坛公园等。
|
|
|
+3. <strong>生成结果:</strong> 最后,Agent会综合信息,给出一个完整的、人性化的回答:“今天北京天气晴朗,微风,非常适合户外游玩。为您推荐前往【颐和园】,您可以在昆明湖上泛舟,欣赏美丽的皇家园林景色。”
|
|
|
|
|
|
-当任务的复杂性超越单个计算实体的能力上限时,分布式协作便成为一种必要的架构选择。在探索人工智能的初期,我们很容易被一个宏大的愿景所吸引:创造一个无所不知、无所不能的<strong>通用人工智能(Artificial General Intelligence)</strong>。然而,当尝试将当前智能体技术应用于真实世界的复杂场景时,全能个体的理想便会遭遇一系列现实挑战。单个通用智能体在应对真实世界的复杂问题时,会遭遇其单体架构带来的一系列挑战:
|
|
|
-
|
|
|
-1. <strong>专业深度的瓶颈</strong> 真实世界的问题往往需要跨领域的深度知识。期望单个智能体同时具备多个领域(如软件工程、市场分析、创意设计)的顶尖专家能力,是不切实际的。这种单一实体承担所有角色的做法,其分析结果往往广度有余,深度不足。
|
|
|
-2. <strong>信息获取的局限</strong> 在分布式系统中,任何单一实体都只能拥有<strong>局部视野(Local View)</strong>,难以掌握全局的、实时的完整信息。例如,一个优化城市交通的智能体,无法瞬间获知每辆车的位置和每个信号灯的状态。基于不完整或延迟的信息进行决策,往往导致结果是次优解。
|
|
|
-3. <strong>系统鲁棒性的脆弱</strong> 单智能体的推理链较为脆弱。如果它在早期阶段做出一个错误的假设,后续所有规划都将建立在这个错误之上。由于缺乏外部的校验和修正机制,它<strong>难以从早期错误中恢复</strong>,可能因单点失败而导致整个任务的崩溃。
|
|
|
-4. <strong>扩展与效率的挑战</strong> 单体架构在可扩展性与效率方面也面临瓶颈。为一个庞大的单体智能体增加新功能,可能需要对核心架构进行复杂的修改。在效率上,它也只能线性处理任务。而通过将任务分解给多个并行的智能体(如Manus AI项目所展示的),则可以实现并行处理,极大提升复杂项目的执行效率。
|
|
|
-
|
|
|
-这些局限性共同指向一个核心问题:试图用中心化的单体架构,去解决本质上分布式、异构的现实世界问题,存在着根本性的错配。<strong>多智能体系统(Multi-Agent System, MAS)</strong>正是为应对这一挑战而生的计算范式。
|
|
|
-
|
|
|
-在学术界,MAS被定义为:一个由多个交互的、自主的智能体组成的计算系统,它们位于共享环境中,通过协作解决单个智能体难以完成的复杂问题。该系统由三个核心要素构成:<strong>智能体(Agent)、环境(Environment)和交互(Interaction)</strong>。鉴于前两部分已有探讨,本节的后续内容将聚焦于MAS的交互,并分析其通信、任务分配与协调策略。更多详细的多智能体介绍将会安排在后面的章节中。
|
|
|
-
|
|
|
-### 1.3.2 多智能体系统的交互机制
|
|
|
-
|
|
|
-本节通过一个具体案例(“为咖啡馆创建网站”)来阐述多智能体交互的三个核心机制:任务规划、通信与协作。
|
|
|
-
|
|
|
-1. 任务规划
|
|
|
-
|
|
|
-多智能体系统的首要步骤是将一个高层级目标映射为可执行的计划。该过程包括任务分解和角色分配。例如,一个“项目经理”智能体接收到初始目标后,其内部生成的规划(`Thought`)如下:
|
|
|
-
|
|
|
-```JSON
|
|
|
-Thought:
|
|
|
-Initial objective: "Create a website for a coffee shop".
|
|
|
-Decomposition:
|
|
|
-1. Frontend Development: Create a static page for the menu and contact info.
|
|
|
-2. Backend Development: Create an API to handle contact form submissions.
|
|
|
-Role Assignment:
|
|
|
-- Assign `FrontendDeveloper` for task 1.
|
|
|
-- Assign `BackendDeveloper` for task 2.
|
|
|
-Next Action: Generate task instruction for `FrontendDeveloper`.
|
|
|
-```
|
|
|
-
|
|
|
-该规划将高层级目标转化为了结构化的子任务和明确的角色分工。
|
|
|
-
|
|
|
-2. 通信机制
|
|
|
-
|
|
|
-规划完成后,各智能体需通过结构化的通信协议交换信息。`项目经理`依据其规划,生成一条 JSON 格式的消息,用于任务分派:
|
|
|
-
|
|
|
-```JSON
|
|
|
-{
|
|
|
- "sender": "ProjectManager",
|
|
|
- "receiver": "FrontendDeveloper",
|
|
|
- "action": "ASSIGN_TASK",
|
|
|
- "data": {
|
|
|
- "task_id": "T-101",
|
|
|
- "description": "Create a static user-facing webpage for the coffee shop. It should include sections for our coffee menu and a contact form.",
|
|
|
- "dependencies": ["Backend_API_for_contact_form"]
|
|
|
- }
|
|
|
-}
|
|
|
-```
|
|
|
-
|
|
|
-JSON作为一种机器可读格式,确保了指令的无歧义性。通信模式可分为直接通信(如API调用)和基于共享内存的间接通信,后者耦合度更低,扩展性更好。
|
|
|
-
|
|
|
-3. 协作策略
|
|
|
-
|
|
|
-协作策略定义了智能体间的工作流与依赖关系。在集中式协调中,存在一个编排者节点,负责任务分发与状态监控。其交互流程如下所示:
|
|
|
-
|
|
|
-```JSON
|
|
|
-1. PM -> FrontendDev: [ASSIGN_TASK T-101: Create frontend page]
|
|
|
-2. PM -> BackendDev: [ASSIGN_TASK T-102: Create backend API]
|
|
|
-3. BackendDev -> PM: [REPORT_STATUS T-102: Complete, API is at /api/contact]
|
|
|
-4. PM -> FrontendDev: [UPDATE_INFO T-101: Backend API is ready, proceed with integration]
|
|
|
-```
|
|
|
-
|
|
|
-该模式下,`项目经理`是控制中心。而在分布式协调中,各智能体节点对等,通过协商来确定行动顺序与资源分配,无需中心节点介入。通过任务规划定义“做什么”,通过通信明确“怎么说”,再通过协作策略管理“如何做”,一个完整的多智能体交互流程便形成了闭环,使一群独立的智能体能够作为一个有凝聚力的整体,共同完成复杂的目标。
|
|
|
-
|
|
|
-### 1.3.3 多智能体系统的演进
|
|
|
-
|
|
|
-早在深度学习革命之前,多智能体系统的主流范式是基于符号主义AI构建的。这一时期的智能体,其智能源于人类专家编码的知识库和推理规则。它们是典型的<strong>基于知识的系统(Knowledge-Based System)</strong>,通过审议式推理(Deliberative Reasoning)进行决策。智能体之间则采用高度形式化的智能体通信语言(ACL)和协调协议(如模拟商业招标的合同网协议)进行交互,确保了通信的精确性和行为的可预测性。不过缺点也比较明显,即为智能体手动构建知识库成本极高(即知识工程瓶颈),且系统面对规则之外的未知情况时表现得非常脆弱。
|
|
|
-
|
|
|
-大语言模型的出现,从根本上重塑了多智能体系统,突破了传统范式的核心瓶颈。
|
|
|
-
|
|
|
-- <strong>从显式知识库到隐式知识库</strong>:LLM通过预训练内化了海量的世界知识,取代了需要手动构建的规则和事实,极大地降低了构建专业智能体的门槛。开发者只需通过<strong>提示工程(Prompt Engineering)</strong>即可“唤醒”其相应能力。
|
|
|
-- <strong>从形式化语言到自然语言交互</strong>:LLM使智能体能以自然语言为主要交互媒介,同时辅以JSON等结构化数据确保参数精确。这极大地提升了交互的灵活性和表现力,也便于人类的理解和介入。
|
|
|
-- <strong>从逻辑匹配到生成式推理</strong>:面对未知情况,LLM能够进行创造性的推理和规划,展现出强大的泛化能力,克服了传统符号系统的脆弱性。
|
|
|
-- <strong>从静态角色到动态角色</strong>:定义一个新角色,对LLM而言可能只是更换一段<strong>系统提示(System Prompt)</strong>,这为构建特质化的智能体团队提供了前所未有的便利。
|
|
|
-
|
|
|
-不过将基于LLM的新范式与传统的符号型范式完全对立起来,是一种过于简化的视角。LLM的出现并非宣告了符号主义的终结,恰恰相反,它为解决符号主义的固有瓶颈提供了新的工具,也让两种范式的融合成为可能。要理解这一点,我们首先需要对二者进行一个直观的对比,如表1.3所示。
|
|
|
-
|
|
|
-<div align="center">
|
|
|
- <p>表 1.3 符号型与LLM驱动的多智能体系统对比</p>
|
|
|
- <img src="https://raw.githubusercontent.com/datawhalechina/Hello-Agents/main/docs/images/1-figures/1757242319667-17.png" alt="图片描述" width="90%"/>
|
|
|
-</div>
|
|
|
+在这个过程中,没有任何写死的`if天气=晴天 then 推荐颐和园`的规则。如果天气是“雨天”,Agent会自主推理并推荐国家博物馆、首都博物馆等室内场所。<strong>这种基于实时信息进行动态推理和决策的能力,正是Agent的核心价值所在。</strong>
|
|
|
|
|
|
-综上,LLM的融入并非局部改良,而是一场范式革命。它将多智能体系统从一个需要被精确编程的、基于知识的系统,转变为一个可通过自然语言引导的、基于能力的通用问题解决器。
|
|
|
|
|
|
-但这并非简单的线性替代,而是一个螺旋上升的融合过程。新旧范式在能力上形成了鲜明的互补:符号主义的严谨、精确、可解释,恰好能弥补LLM的灵活性有余而可靠性不足(如“幻觉”问题)。因此,未来的前沿方向,很可能就是将LLM的归纳推理能力与符号系统的演绎推理能力深度结合,例如让LLM负责生成初步方案,再由符号系统进行严格的验证和约束。通过这种融合,在创造力与精确性、灵活性与可靠性之间取得更好的平衡,从而构建出更值得信赖的多智能体系统。
|
|
|
|
|
|
## 1.4 本章小结
|
|
|
|
|
|
在本章中,我们共同踏上了探索智能体的初识之旅。我们的旅程从最基本的问题开始:
|
|
|
|
|
|
-- <strong>什么是智能体?</strong> 我们首先回顾了其在传统计算机科学中的定义,随后将焦点转向了由大语言模型驱动的智能体,理解了现代智能体所具备的感知、推理与行动能力。
|
|
|
-- <strong>智能体如何分类?</strong> 我们从内部决策架构、时间反应性以及知识表示等多个维度,对智能体进行了系统的分类。这为我们理解不同智能体的特性和适用场景打下了坚实的基础。
|
|
|
-- <strong>智能体如何工作?</strong> 我们深入探讨了智能体与环境交互的核心机制,行动循环。通过“感知-规划-行动-学习”的闭环,智能体得以在复杂的环境中完成任务。结合AgentGPT等真实案例,可以直观地看到了智能体在不同场景和不同设计模式下的具体体现。
|
|
|
-- <strong>智能体如何协作?</strong> 最后,我们将视野从单个智能体扩展到了由多个智能体组成的多智能体系统。不仅探讨了其协作的核心要素(如通信、任务分配与协调),还讲述了多智能体系统的演进过程。
|
|
|
+- <strong>什么是大语言模型驱动的智能体?</strong> 我们首先明确了其定义,理解了现代智能体是具备了能力的实体。它不再仅仅是执行预设程序的脚本,而是能够自主推理和使用工具的决策者。
|
|
|
+- <strong>智能体如何工作?</strong> 我们深入探讨了智能体与环境交互的运行机制。我们了解到,这个持续的闭环是智能体处理信息、做出决策、影响环境并根据反馈调整自身行为的基础。
|
|
|
+- <strong>如何构建智能体?</strong> 这是本章的实践核心。我们以“智能旅行助手”为例,亲手构建了一个完整的、由真实LLM驱动的智能体。
|
|
|
+- <strong>智能体有哪些主流的应用范式?</strong> 最后,我们将视野投向了更广阔的应用领域。我们探讨了两种主流的智能体交互模式:一是以GitHub Copilot和Cursor等为代表的、增强人类工作流的“开发者工具”;二是以CrewAI、MetaGPT和AgentScope等框架为代表的、能够独立完成高层级目标的“自主协作者”。同时讲解了Workflow与Agent的差异。
|
|
|
|
|
|
-通过本章的学习,我们建立了一个关于智能体的基础认知框架:<strong>从单个智能体的定义与分类,到其与环境的交互,再到多智能体系统的协作模式</strong>。那么,它是如何一步步从最初的构想演进至今的呢?在下一章中,我们将探索智能体的发展历史,一段追本溯源的旅程即将开始!
|
|
|
+通过本章的学习,我们建立了一个关于智能体的基础认知框架。那么,它是如何一步步从最初的构想演进至今的呢?在下一章中,我们将探索智能体的发展历史,一段追本溯源的旅程即将开始!
|
|
|
|
|
|
## 参考文献
|
|
|
|

 jjyaoao
jjyaoao
{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}
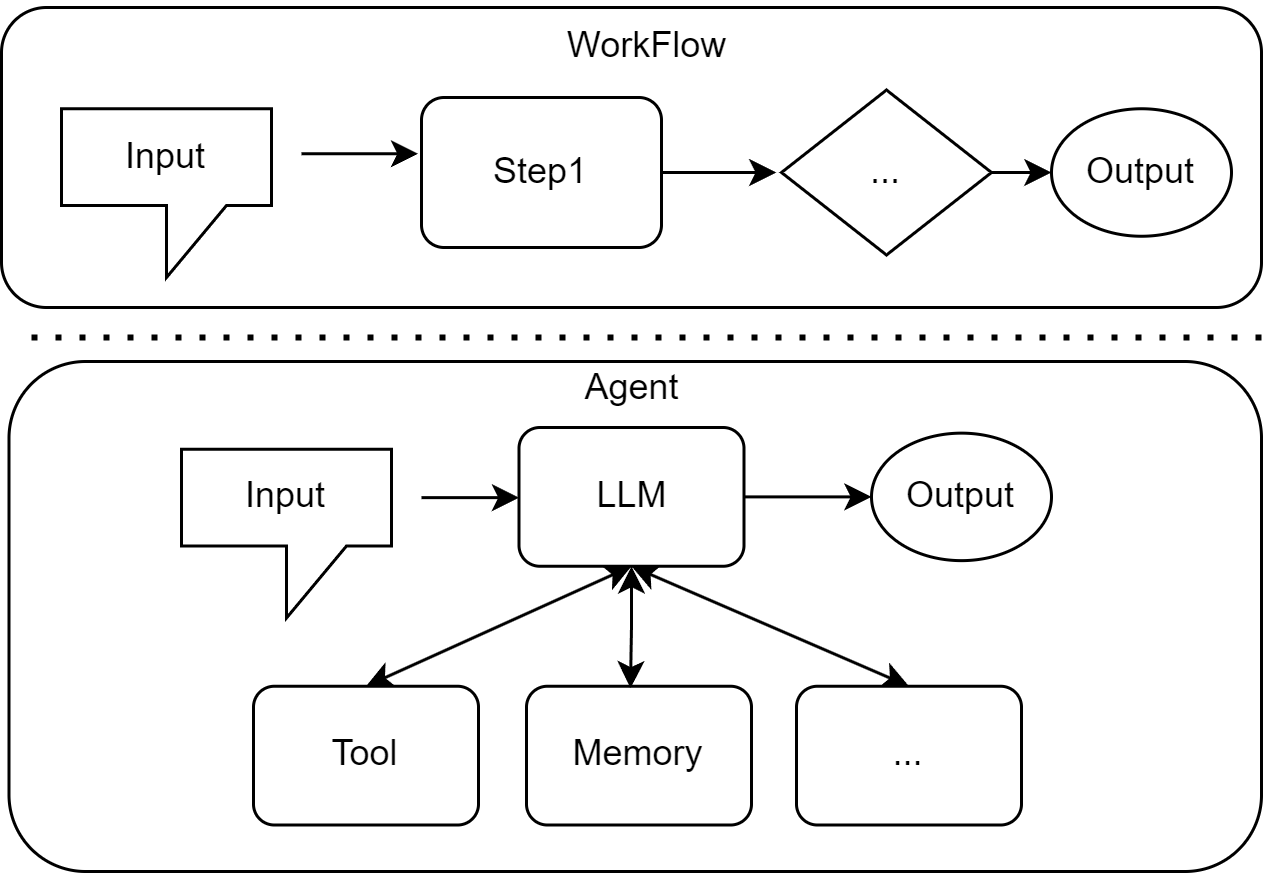
{kind=link}

{kind=link}

{kind=link}
