|
|
@@ -0,0 +1,1809 @@
|
|
|
+"""Custom agent runner and scientific ReAct controller."""
|
|
|
+
|
|
|
+from __future__ import annotations
|
|
|
+
|
|
|
+import contextlib
|
|
|
+import io
|
|
|
+import json
|
|
|
+import re
|
|
|
+import time
|
|
|
+from dataclasses import asdict, dataclass, field
|
|
|
+from datetime import datetime
|
|
|
+from pathlib import Path
|
|
|
+from typing import Any, Callable, Optional
|
|
|
+
|
|
|
+from hello_agents import ToolRegistry
|
|
|
+
|
|
|
+from .config import RuntimeConfig, load_runtime_config
|
|
|
+from .data_context import DataContextSummary, build_data_context
|
|
|
+from .document_ingestion import IngestionResult, ingest_input_document
|
|
|
+from .llm import build_llm
|
|
|
+from .prompts import (
|
|
|
+ DEFAULT_QUERY,
|
|
|
+ build_observation_prompt,
|
|
|
+ build_reviewer_prompt,
|
|
|
+ build_response_format_feedback,
|
|
|
+ build_system_prompt,
|
|
|
+)
|
|
|
+from .reporting import (
|
|
|
+ ReportTelemetry,
|
|
|
+ extract_report_and_telemetry,
|
|
|
+ save_markdown_report,
|
|
|
+)
|
|
|
+from .tools.python_interpreter import PythonInterpreterTool
|
|
|
+from .tools.tavily_search import TavilySearchTool
|
|
|
+from .vision_review import VisualReviewResult, run_visual_review
|
|
|
+
|
|
|
+
|
|
|
+EventHandler = Callable[[str, dict[str, Any]], None]
|
|
|
+
|
|
|
+
|
|
|
+@dataclass(frozen=True)
|
|
|
+class AgentStepTrace:
|
|
|
+ step_index: int
|
|
|
+ raw_response: str
|
|
|
+ action: str
|
|
|
+ decision: str = ""
|
|
|
+ tool_name: Optional[str] = None
|
|
|
+ tool_status: str = "unknown"
|
|
|
+ observation: Optional[str] = None
|
|
|
+ observation_preview: str = ""
|
|
|
+ summary: str = ""
|
|
|
+ parse_error: Optional[str] = None
|
|
|
+ llm_duration_ms: int = 0
|
|
|
+ tool_duration_ms: int = 0
|
|
|
+
|
|
|
+
|
|
|
+@dataclass(frozen=True)
|
|
|
+class ParsedAgentReply:
|
|
|
+ action: str
|
|
|
+ decision: str
|
|
|
+ tool_name: str = ""
|
|
|
+ tool_input: str = ""
|
|
|
+ final_answer: str = ""
|
|
|
+
|
|
|
+
|
|
|
+@dataclass(frozen=True)
|
|
|
+class ParsedReviewerReply:
|
|
|
+ decision: str
|
|
|
+ critique: str
|
|
|
+ raw_response: str = ""
|
|
|
+
|
|
|
+
|
|
|
+@dataclass(frozen=True)
|
|
|
+class ArtifactValidationResult:
|
|
|
+ workflow_complete: bool
|
|
|
+ missing_artifacts: tuple[str, ...]
|
|
|
+ warnings: tuple[str, ...]
|
|
|
+ cleaned_data_exists: bool
|
|
|
+ report_exists: bool
|
|
|
+ trace_exists: bool
|
|
|
+
|
|
|
+
|
|
|
+@dataclass(frozen=True)
|
|
|
+class ReviewRecord:
|
|
|
+ round_index: int
|
|
|
+ decision: str
|
|
|
+ critique: str
|
|
|
+ raw_response: str
|
|
|
+ review_log_path: Path
|
|
|
+ candidate_report_path: Path
|
|
|
+
|
|
|
+
|
|
|
+@dataclass(frozen=True)
|
|
|
+class VisualReviewRecord:
|
|
|
+ round_index: int
|
|
|
+ status: str
|
|
|
+ decision: str
|
|
|
+ summary: str
|
|
|
+ figures_reviewed: tuple[str, ...]
|
|
|
+ skipped_figures: tuple[str, ...]
|
|
|
+ duration_ms: int
|
|
|
+ raw_response: str
|
|
|
+ warning: str
|
|
|
+ log_path: Path
|
|
|
+
|
|
|
+
|
|
|
+@dataclass(frozen=True)
|
|
|
+class AnalystRoundRecord:
|
|
|
+ round_index: int
|
|
|
+ report_path: Path
|
|
|
+ step_traces: tuple[AgentStepTrace, ...]
|
|
|
+
|
|
|
+
|
|
|
+@dataclass(frozen=True)
|
|
|
+class AnalysisRunResult:
|
|
|
+ data_context: DataContextSummary
|
|
|
+ raw_result: str
|
|
|
+ report_markdown: str
|
|
|
+ report_path: Path
|
|
|
+ output_dir: Path
|
|
|
+ run_dir: Path
|
|
|
+ data_dir: Path
|
|
|
+ figures_dir: Path
|
|
|
+ logs_dir: Path
|
|
|
+ trace_path: Path
|
|
|
+ cleaned_data_path: Path
|
|
|
+ agent_type: str
|
|
|
+ step_traces: tuple[AgentStepTrace, ...]
|
|
|
+ telemetry: ReportTelemetry
|
|
|
+ methods_used: tuple[str, ...]
|
|
|
+ detected_domain: str
|
|
|
+ tools_used: tuple[str, ...]
|
|
|
+ search_status: str
|
|
|
+ search_notes: str
|
|
|
+ workflow_complete: bool
|
|
|
+ workflow_warnings: tuple[str, ...]
|
|
|
+ missing_artifacts: tuple[str, ...]
|
|
|
+ quality_mode: str
|
|
|
+ review_enabled: bool
|
|
|
+ review_status: str
|
|
|
+ review_rounds_used: int
|
|
|
+ review_critique: str
|
|
|
+ review_log_paths: tuple[Path, ...]
|
|
|
+ input_kind: str = "tabular"
|
|
|
+ document_ingestion_status: str = "not_needed"
|
|
|
+ document_ingestion_summary: str = ""
|
|
|
+ document_ingestion_duration_ms: int = 0
|
|
|
+ document_ingestion_log_path: Path | None = None
|
|
|
+ candidate_table_count: int = 0
|
|
|
+ selected_table_id: str = ""
|
|
|
+ selected_table_shape: tuple[int, int] | None = None
|
|
|
+ pdf_multi_table_mode: bool = False
|
|
|
+ latency_mode: str = "auto"
|
|
|
+ vision_review_mode: str = "auto"
|
|
|
+ vision_review_enabled: bool = False
|
|
|
+ vision_review_status: str = "skipped"
|
|
|
+ vision_review_summary: str = ""
|
|
|
+ vision_review_duration_ms: int = 0
|
|
|
+ vision_review_log_paths: tuple[Path, ...] = ()
|
|
|
+ total_duration_ms: int = 0
|
|
|
+ llm_duration_ms: int = 0
|
|
|
+ tool_duration_ms: int = 0
|
|
|
+ review_duration_ms: int = 0
|
|
|
+ timing_breakdown: dict[str, int] = field(default_factory=dict)
|
|
|
+
|
|
|
+
|
|
|
+def _emit_event(event_handler: Optional[EventHandler], event_type: str, **payload: Any) -> None:
|
|
|
+ if event_handler is not None:
|
|
|
+ event_handler(event_type, payload)
|
|
|
+
|
|
|
+
|
|
|
+def build_plaintext_event_handler() -> EventHandler:
|
|
|
+ """Build a lightweight stdout event handler for notebooks and scripts."""
|
|
|
+
|
|
|
+ def handle_event(event_type: str, payload: dict[str, Any]) -> None:
|
|
|
+ if event_type == "config_loading":
|
|
|
+ print("[1/7] Loading runtime configuration...")
|
|
|
+ elif event_type == "config_loaded":
|
|
|
+ if payload.get("tavily_configured"):
|
|
|
+ print(f" Model: {payload.get('model_id', 'unknown')} | Tavily credential: detected")
|
|
|
+ else:
|
|
|
+ print(f" Model: {payload.get('model_id', 'unknown')} | Tavily search: skipped unless configured")
|
|
|
+ print(f" Latency mode: {payload.get('latency_mode', 'auto')}")
|
|
|
+ print(f" Vision review: {'configured' if payload.get('vision_configured') else 'not configured'}")
|
|
|
+ elif event_type == "run_directory_created":
|
|
|
+ print("[2/7] Created production run directory...")
|
|
|
+ print(f" Run root: {payload.get('run_dir', '')}")
|
|
|
+ elif event_type == "document_ingestion_started":
|
|
|
+ print("[3/7] Running input document ingestion...")
|
|
|
+ print(f" Input kind: {payload.get('input_kind', 'unknown')}")
|
|
|
+ elif event_type == "document_ingestion_completed":
|
|
|
+ print(f" Document ingestion completed | status = {payload.get('status', 'unknown')}")
|
|
|
+ print(f" Summary: {payload.get('summary', '')}")
|
|
|
+ elif event_type == "document_ingestion_skipped":
|
|
|
+ print(" Document ingestion skipped: input is already tabular.")
|
|
|
+ elif event_type == "data_context_loading":
|
|
|
+ print("[4/7] Building compact dataset metadata context...")
|
|
|
+ elif event_type == "data_context_ready":
|
|
|
+ shape = payload.get("shape", ("?", "?"))
|
|
|
+ print(f" Data shape: {shape[0]} rows x {shape[1]} columns")
|
|
|
+ elif event_type == "tool_registry_ready":
|
|
|
+ print(f"[5/7] Tool registry ready: {', '.join(payload.get('tools', []))}")
|
|
|
+ print(
|
|
|
+ f" Fast path: {payload.get('fast_path_enabled', False)} | "
|
|
|
+ f"effective max steps: {payload.get('effective_max_steps', '?')}"
|
|
|
+ )
|
|
|
+ elif event_type == "analysis_started":
|
|
|
+ print(f"[6/7] {payload.get('agent_name', 'Agent')} started reasoning (max steps = {payload.get('max_steps', '?')})")
|
|
|
+ if payload.get("analysis_round"):
|
|
|
+ print(f" Analysis round: {payload.get('analysis_round')}")
|
|
|
+ elif event_type == "step_started":
|
|
|
+ print(f" Step {payload.get('step_index', '?')}/{payload.get('max_steps', '?')}: thinking...")
|
|
|
+ elif event_type == "tool_call_started":
|
|
|
+ tool_name = payload.get("tool_name", "UnknownTool")
|
|
|
+ decision = payload.get("decision", "")
|
|
|
+ print(f" Calling {tool_name} | {decision}")
|
|
|
+ elif event_type == "tool_call_completed":
|
|
|
+ print(f" Completed {payload.get('tool_name', 'UnknownTool')} | status = {payload.get('tool_status', 'unknown')}")
|
|
|
+ preview = payload.get("observation_preview")
|
|
|
+ if preview:
|
|
|
+ print(f" Observation: {preview}")
|
|
|
+ elif event_type == "step_parse_error":
|
|
|
+ print(f" Protocol parse warning: {payload.get('message', '')}")
|
|
|
+ elif event_type == "report_persisting":
|
|
|
+ print("[7/7] Saving Markdown report and run trace...")
|
|
|
+ elif event_type == "report_saved":
|
|
|
+ print(f" Final report: {payload.get('report_path', '')}")
|
|
|
+ print(f" Agent trace: {payload.get('trace_path', '')}")
|
|
|
+ elif event_type == "artifact_validation_completed":
|
|
|
+ if payload.get("workflow_complete"):
|
|
|
+ print("[8/8] Production artifact validation passed.")
|
|
|
+ else:
|
|
|
+ print("[8/8] Production artifact validation failed.")
|
|
|
+ print(f" Missing: {', '.join(payload.get('missing_artifacts', []))}")
|
|
|
+ elif event_type == "analysis_finished":
|
|
|
+ print(" Final report generated successfully.")
|
|
|
+ elif event_type == "analysis_max_steps":
|
|
|
+ print(" Agent hit the max-step limit and returned a fallback report.")
|
|
|
+ elif event_type == "vision_review_started":
|
|
|
+ print(f" Vision reviewer round {payload.get('review_round', '?')} started.")
|
|
|
+ elif event_type == "vision_review_completed":
|
|
|
+ print(
|
|
|
+ f" Vision reviewer completed | status = {payload.get('status', 'unknown')} | "
|
|
|
+ f"decision = {payload.get('decision', 'unknown')}"
|
|
|
+ )
|
|
|
+ elif event_type == "vision_review_skipped":
|
|
|
+ print(f" Vision reviewer skipped: {payload.get('reason', '')}")
|
|
|
+ elif event_type == "review_started":
|
|
|
+ print(f" Reviewer round {payload.get('review_round', '?')} started.")
|
|
|
+ elif event_type == "review_rejected":
|
|
|
+ print(f" [REJECT] 审稿人意见:{payload.get('critique', '')}")
|
|
|
+ elif event_type == "review_accepted":
|
|
|
+ print(" [OK] 审稿通过:报告达到当前质量档位要求。")
|
|
|
+ elif event_type == "review_max_reached":
|
|
|
+ print(" Reviewer max rounds reached. Final report was not formally accepted.")
|
|
|
+
|
|
|
+ return handle_event
|
|
|
+
|
|
|
+
|
|
|
+def build_tool_registry(*, enable_search: bool = True) -> ToolRegistry:
|
|
|
+ """Create the tool registry for the analysis agent."""
|
|
|
+
|
|
|
+ tool_registry = ToolRegistry()
|
|
|
+ for deprecated_tool_name in ("DataCleaningTool", "DataStatisticsTool", "python_interpreter_tool"):
|
|
|
+ tool_registry._tools.pop(deprecated_tool_name, None)
|
|
|
+ tool_registry._functions.pop(deprecated_tool_name, None)
|
|
|
+
|
|
|
+ with contextlib.redirect_stdout(io.StringIO()):
|
|
|
+ tool_registry.register_tool(PythonInterpreterTool())
|
|
|
+ if enable_search:
|
|
|
+ tool_registry.register_tool(TavilySearchTool())
|
|
|
+ return tool_registry
|
|
|
+
|
|
|
+
|
|
|
+def _elapsed_ms(start_time: float) -> int:
|
|
|
+ return int(round((time.perf_counter() - start_time) * 1000))
|
|
|
+
|
|
|
+
|
|
|
+def _accumulate_duration(timing_breakdown: dict[str, int], key: str, duration_ms: int) -> None:
|
|
|
+ timing_breakdown[key] = timing_breakdown.get(key, 0) + max(0, int(duration_ms))
|
|
|
+
|
|
|
+
|
|
|
+def _truncate_text(text: str, limit: int) -> str:
|
|
|
+ normalized = str(text or "").strip()
|
|
|
+ if len(normalized) <= limit:
|
|
|
+ return normalized
|
|
|
+ return normalized[:limit].rstrip() + " ... [truncated]"
|
|
|
+
|
|
|
+
|
|
|
+def _build_observation_summary(
|
|
|
+ *,
|
|
|
+ tool_name: str,
|
|
|
+ observation: str,
|
|
|
+ tool_status: str,
|
|
|
+ observation_preview: str,
|
|
|
+) -> str:
|
|
|
+ try:
|
|
|
+ payload = json.loads(observation)
|
|
|
+ except Exception:
|
|
|
+ return (
|
|
|
+ f"Status: {tool_status}\n"
|
|
|
+ f"Preview: {_truncate_text(observation_preview or observation, 300)}"
|
|
|
+ )
|
|
|
+
|
|
|
+ text = str(payload.get("text", "")).strip()
|
|
|
+ data = payload.get("data", {})
|
|
|
+ parts = [
|
|
|
+ f"Status: {tool_status}",
|
|
|
+ f"Preview: {_truncate_text(observation_preview or text, 300)}",
|
|
|
+ ]
|
|
|
+
|
|
|
+ if tool_name == "PythonInterpreterTool" and isinstance(data, dict):
|
|
|
+ stdout_text = _truncate_text(str(data.get("stdout", "")).strip(), 1200)
|
|
|
+ stderr_text = _truncate_text(str(data.get("stderr", "")).strip(), 800)
|
|
|
+ warning_messages = data.get("warnings", [])
|
|
|
+ if stdout_text:
|
|
|
+ parts.append(f"Stdout:\n{stdout_text}")
|
|
|
+ if stderr_text:
|
|
|
+ parts.append(f"Stderr:\n{stderr_text}")
|
|
|
+ if isinstance(warning_messages, list) and warning_messages:
|
|
|
+ warnings_block = "\n".join(f"- {item}" for item in warning_messages[:5])
|
|
|
+ if len(warning_messages) > 5:
|
|
|
+ warnings_block += f"\n- ... {len(warning_messages) - 5} more warning(s) omitted."
|
|
|
+ parts.append(f"Warnings:\n{warnings_block}")
|
|
|
+ return "\n\n".join(parts)
|
|
|
+
|
|
|
+ if tool_name == "TavilySearchTool" and isinstance(data, dict):
|
|
|
+ query = str(data.get("query", "")).strip()
|
|
|
+ results = data.get("results", [])
|
|
|
+ if query:
|
|
|
+ parts.append(f"Query: {query}")
|
|
|
+ if isinstance(results, list) and results:
|
|
|
+ result_lines = []
|
|
|
+ for index, item in enumerate(results[:3], start=1):
|
|
|
+ if not isinstance(item, dict):
|
|
|
+ continue
|
|
|
+ title = _truncate_text(str(item.get("title", "Untitled")).strip(), 80)
|
|
|
+ url = _truncate_text(str(item.get("url", "")).strip(), 120)
|
|
|
+ snippet_source = item.get("content", item.get("snippet", ""))
|
|
|
+ snippet = _truncate_text(str(snippet_source).strip(), 200)
|
|
|
+ line = f"{index}. {title}"
|
|
|
+ if url:
|
|
|
+ line += f" | {url}"
|
|
|
+ if snippet:
|
|
|
+ line += f" | {snippet}"
|
|
|
+ result_lines.append(line)
|
|
|
+ if result_lines:
|
|
|
+ parts.append("Top search results:\n" + "\n".join(result_lines))
|
|
|
+ if len(results) > 3:
|
|
|
+ parts.append(f"... {len(results) - 3} more result(s) omitted.")
|
|
|
+ return "\n\n".join(parts)
|
|
|
+
|
|
|
+ if text:
|
|
|
+ parts.append(f"Observation text:\n{_truncate_text(text, 1200)}")
|
|
|
+ return "\n\n".join(parts)
|
|
|
+
|
|
|
+
|
|
|
+def _resolve_latency_mode(latency_mode: str) -> str:
|
|
|
+ normalized_mode = latency_mode.strip().lower()
|
|
|
+ if normalized_mode not in {"auto", "quality", "fast"}:
|
|
|
+ raise ValueError(f"Unsupported latency_mode: {latency_mode}")
|
|
|
+ return normalized_mode
|
|
|
+
|
|
|
+
|
|
|
+def _resolve_vision_review_mode(vision_review_mode: str) -> str:
|
|
|
+ normalized_mode = vision_review_mode.strip().lower()
|
|
|
+ if normalized_mode not in {"off", "auto", "on"}:
|
|
|
+ raise ValueError(f"Unsupported vision_review_mode: {vision_review_mode}")
|
|
|
+ return normalized_mode
|
|
|
+
|
|
|
+
|
|
|
+def _is_small_simple_dataset(data_context: DataContextSummary) -> bool:
|
|
|
+ try:
|
|
|
+ file_size_bytes = data_context.absolute_path.stat().st_size
|
|
|
+ except OSError:
|
|
|
+ file_size_bytes = 0
|
|
|
+ rows, cols = data_context.shape
|
|
|
+ return file_size_bytes <= 512 * 1024 and rows <= 2000 and cols <= 50
|
|
|
+
|
|
|
+
|
|
|
+def _should_use_fast_path(latency_mode: str, *, small_simple_dataset: bool) -> bool:
|
|
|
+ return latency_mode == "fast" or (latency_mode == "auto" and small_simple_dataset)
|
|
|
+
|
|
|
+
|
|
|
+def _resolve_effective_max_steps(
|
|
|
+ *,
|
|
|
+ requested_max_steps: int,
|
|
|
+ quality_mode: str,
|
|
|
+ latency_mode: str,
|
|
|
+ small_simple_dataset: bool,
|
|
|
+) -> int:
|
|
|
+ if not _should_use_fast_path(latency_mode, small_simple_dataset=small_simple_dataset):
|
|
|
+ return requested_max_steps
|
|
|
+ caps = {
|
|
|
+ "draft": 3,
|
|
|
+ "standard": 4,
|
|
|
+ "publication": 5,
|
|
|
+ }
|
|
|
+ return min(requested_max_steps, caps[quality_mode])
|
|
|
+
|
|
|
+
|
|
|
+_SEARCH_SIGNAL_KEYWORDS = (
|
|
|
+ "clinical",
|
|
|
+ "biomarker",
|
|
|
+ "chromosome",
|
|
|
+ "nipt",
|
|
|
+ "cpi",
|
|
|
+ "ppv",
|
|
|
+ "odds ratio",
|
|
|
+ "临床",
|
|
|
+ "阈值",
|
|
|
+ "正常范围",
|
|
|
+ "染色体",
|
|
|
+ "宏观",
|
|
|
+ "统计口径",
|
|
|
+)
|
|
|
+
|
|
|
+
|
|
|
+def _should_enable_search(
|
|
|
+ *,
|
|
|
+ runtime_config: RuntimeConfig,
|
|
|
+ data_context: DataContextSummary,
|
|
|
+ query: str,
|
|
|
+ quality_mode: str,
|
|
|
+ latency_mode: str,
|
|
|
+) -> bool:
|
|
|
+ if not runtime_config.tavily_api_key:
|
|
|
+ return False
|
|
|
+ if latency_mode == "quality":
|
|
|
+ return True
|
|
|
+
|
|
|
+ searchable_text = " ".join([query, *data_context.columns])
|
|
|
+ lowered = searchable_text.lower()
|
|
|
+ if any(keyword in lowered for keyword in _SEARCH_SIGNAL_KEYWORDS):
|
|
|
+ return True
|
|
|
+ if re.search(r"\b[A-Z]{2,}[0-9A-Z/_-]*\b", searchable_text):
|
|
|
+ return True
|
|
|
+ return False
|
|
|
+
|
|
|
+
|
|
|
+def _extract_first_json_object(text: str) -> str:
|
|
|
+ stripped = text.strip()
|
|
|
+ if not stripped:
|
|
|
+ raise ValueError("Model returned an empty response.")
|
|
|
+
|
|
|
+ if stripped.startswith("```"):
|
|
|
+ fence_lines = stripped.splitlines()
|
|
|
+ if len(fence_lines) >= 3 and fence_lines[0].startswith("```") and fence_lines[-1].startswith("```"):
|
|
|
+ stripped = "\n".join(fence_lines[1:-1]).strip()
|
|
|
+
|
|
|
+ start = stripped.find("{")
|
|
|
+ if start == -1:
|
|
|
+ raise ValueError("No JSON object found in model response.")
|
|
|
+
|
|
|
+ depth = 0
|
|
|
+ in_string = False
|
|
|
+ escape = False
|
|
|
+
|
|
|
+ for index in range(start, len(stripped)):
|
|
|
+ char = stripped[index]
|
|
|
+ if escape:
|
|
|
+ escape = False
|
|
|
+ continue
|
|
|
+ if char == "\\":
|
|
|
+ escape = True
|
|
|
+ continue
|
|
|
+ if char == '"':
|
|
|
+ in_string = not in_string
|
|
|
+ continue
|
|
|
+ if in_string:
|
|
|
+ continue
|
|
|
+ if char == "{":
|
|
|
+ depth += 1
|
|
|
+ elif char == "}":
|
|
|
+ depth -= 1
|
|
|
+ if depth == 0:
|
|
|
+ return stripped[start : index + 1]
|
|
|
+
|
|
|
+ raise ValueError("Unterminated JSON object in model response.")
|
|
|
+
|
|
|
+
|
|
|
+def _parse_agent_reply(raw_response: str) -> ParsedAgentReply:
|
|
|
+ json_payload = _extract_first_json_object(raw_response)
|
|
|
+
|
|
|
+ try:
|
|
|
+ payload = json.loads(json_payload)
|
|
|
+ except json.JSONDecodeError as exc:
|
|
|
+ raise ValueError(f"Invalid JSON response: {exc}") from exc
|
|
|
+
|
|
|
+ if not isinstance(payload, dict):
|
|
|
+ raise ValueError("Model response JSON must be an object.")
|
|
|
+
|
|
|
+ action = str(payload.get("action", "")).strip().lower()
|
|
|
+ if action not in {"call_tool", "finish"}:
|
|
|
+ raise ValueError("Field 'action' must be either 'call_tool' or 'finish'.")
|
|
|
+
|
|
|
+ decision = str(payload.get("decision", "")).strip()
|
|
|
+
|
|
|
+ if action == "call_tool":
|
|
|
+ tool_name = str(payload.get("tool_name", "")).strip()
|
|
|
+ tool_input = str(payload.get("tool_input", "")).strip()
|
|
|
+ if not tool_name:
|
|
|
+ raise ValueError("Field 'tool_name' is required when action is 'call_tool'.")
|
|
|
+ if not tool_input:
|
|
|
+ raise ValueError("Field 'tool_input' is required when action is 'call_tool'.")
|
|
|
+ return ParsedAgentReply(
|
|
|
+ action=action,
|
|
|
+ decision=decision,
|
|
|
+ tool_name=tool_name,
|
|
|
+ tool_input=tool_input,
|
|
|
+ final_answer="",
|
|
|
+ )
|
|
|
+
|
|
|
+ final_answer = str(payload.get("final_answer", "")).strip()
|
|
|
+ if not final_answer:
|
|
|
+ raise ValueError("Field 'final_answer' is required when action is 'finish'.")
|
|
|
+
|
|
|
+ return ParsedAgentReply(
|
|
|
+ action=action,
|
|
|
+ decision=decision,
|
|
|
+ final_answer=final_answer,
|
|
|
+ )
|
|
|
+
|
|
|
+
|
|
|
+def _parse_reviewer_reply(raw_response: str) -> ParsedReviewerReply:
|
|
|
+ json_payload = _extract_first_json_object(raw_response)
|
|
|
+
|
|
|
+ try:
|
|
|
+ payload = json.loads(json_payload)
|
|
|
+ except json.JSONDecodeError as exc:
|
|
|
+ raise ValueError(f"Invalid reviewer JSON response: {exc}") from exc
|
|
|
+
|
|
|
+ if not isinstance(payload, dict):
|
|
|
+ raise ValueError("Reviewer response JSON must be an object.")
|
|
|
+
|
|
|
+ decision = str(payload.get("decision", "")).strip()
|
|
|
+ if decision not in {"Accept", "Reject"}:
|
|
|
+ raise ValueError("Reviewer field 'decision' must be either 'Accept' or 'Reject'.")
|
|
|
+
|
|
|
+ critique = str(payload.get("critique", "")).strip()
|
|
|
+ if not critique:
|
|
|
+ raise ValueError("Reviewer field 'critique' must be a non-empty string.")
|
|
|
+
|
|
|
+ return ParsedReviewerReply(decision=decision, critique=critique, raw_response=raw_response)
|
|
|
+
|
|
|
+
|
|
|
+def _safe_parse_reviewer_reply(raw_response: str) -> ParsedReviewerReply:
|
|
|
+ try:
|
|
|
+ return _parse_reviewer_reply(raw_response)
|
|
|
+ except ValueError as exc:
|
|
|
+ critique = (
|
|
|
+ "Reviewer response could not be parsed. Treat this as a rejection and revise the report. "
|
|
|
+ f"Parsing issue: {exc}"
|
|
|
+ )
|
|
|
+ return ParsedReviewerReply(decision="Reject", critique=critique, raw_response=raw_response)
|
|
|
+
|
|
|
+
|
|
|
+def _parse_tool_observation(observation: str) -> tuple[str, str]:
|
|
|
+ try:
|
|
|
+ payload = json.loads(observation)
|
|
|
+ except Exception:
|
|
|
+ preview = " ".join(observation.split())
|
|
|
+ return "unknown", preview[:220]
|
|
|
+
|
|
|
+ status = str(payload.get("status", "unknown")).strip() or "unknown"
|
|
|
+ preview = " ".join(str(payload.get("text", "")).split())
|
|
|
+ return status, preview[:220]
|
|
|
+
|
|
|
+
|
|
|
+def _build_step_summary(tool_name: str, decision: str, tool_status: str, observation_preview: str) -> str:
|
|
|
+ if tool_name == "TavilySearchTool":
|
|
|
+ action_text = "Online domain knowledge retrieval"
|
|
|
+ elif tool_name == "PythonInterpreterTool":
|
|
|
+ action_text = "Local Python execution"
|
|
|
+ else:
|
|
|
+ action_text = f"Tool call: {tool_name}"
|
|
|
+
|
|
|
+ summary = f"{action_text} | status={tool_status}"
|
|
|
+ if decision:
|
|
|
+ summary = f"{summary} | decision={decision}"
|
|
|
+ if observation_preview:
|
|
|
+ summary = f"{summary} | observation={observation_preview}"
|
|
|
+ return summary
|
|
|
+
|
|
|
+
|
|
|
+def _determine_search_status(step_traces: tuple[AgentStepTrace, ...], telemetry: ReportTelemetry) -> tuple[str, str]:
|
|
|
+ tavily_steps = [trace for trace in step_traces if trace.tool_name == "TavilySearchTool"]
|
|
|
+ if telemetry.valid and telemetry.search_used:
|
|
|
+ return "used", telemetry.search_notes
|
|
|
+ if not tavily_steps:
|
|
|
+ if telemetry.valid and telemetry.search_notes != "unknown":
|
|
|
+ return "not_used", telemetry.search_notes
|
|
|
+ return "not_used", "No online knowledge retrieval was triggered."
|
|
|
+
|
|
|
+ combined_preview = " ".join(trace.observation_preview for trace in tavily_steps).lower()
|
|
|
+ if "no tavily search credential" in combined_preview:
|
|
|
+ return "skipped", "Tavily credential is not configured, so online search was skipped."
|
|
|
+ if "temporarily unavailable" in combined_preview or "dependency is unavailable" in combined_preview:
|
|
|
+ return "unavailable", "Online retrieval was unavailable; the agent fell back to local analysis."
|
|
|
+ if any(trace.tool_status == "success" for trace in tavily_steps):
|
|
|
+ return "used", telemetry.search_notes if telemetry.search_notes != "unknown" else "Online search results were incorporated."
|
|
|
+ return "attempted", telemetry.search_notes if telemetry.search_notes != "unknown" else "Online search was attempted but did not yield stable results."
|
|
|
+
|
|
|
+
|
|
|
+def _collect_tools_used(step_traces: tuple[AgentStepTrace, ...], telemetry: ReportTelemetry) -> tuple[str, ...]:
|
|
|
+ if telemetry.tools_used:
|
|
|
+ return telemetry.tools_used
|
|
|
+ tool_names = []
|
|
|
+ for trace in step_traces:
|
|
|
+ if trace.tool_name and trace.tool_name not in tool_names:
|
|
|
+ tool_names.append(trace.tool_name)
|
|
|
+ return tuple(tool_names)
|
|
|
+
|
|
|
+
|
|
|
+def _create_run_directory(output_dir: str | Path) -> tuple[Path, Path, Path, Path]:
|
|
|
+ parent_dir = Path(output_dir)
|
|
|
+ timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
|
|
+ run_dir = parent_dir / f"run_{timestamp}"
|
|
|
+ data_dir = run_dir / "data"
|
|
|
+ figures_dir = run_dir / "figures"
|
|
|
+ logs_dir = run_dir / "logs"
|
|
|
+ for directory in (data_dir, figures_dir, logs_dir):
|
|
|
+ directory.mkdir(parents=True, exist_ok=True)
|
|
|
+ return run_dir, data_dir, figures_dir, logs_dir
|
|
|
+
|
|
|
+
|
|
|
+def _build_run_context_text(run_dir: Path, cleaned_data_path: Path, figures_dir: Path, logs_dir: Path) -> str:
|
|
|
+ return (
|
|
|
+ f"\n本次任务的专属输出根目录为:{run_dir.as_posix()}\n"
|
|
|
+ f"清洗后的数据必须保存到:{cleaned_data_path.as_posix()}\n"
|
|
|
+ f"所有图表必须保存到:{figures_dir.as_posix()}\n"
|
|
|
+ f"运行轨迹与日志目录为:{logs_dir.as_posix()}\n"
|
|
|
+ "请务必严格遵守“先清洗落盘,再重读分析”的两阶段流水线。\n"
|
|
|
+ )
|
|
|
+
|
|
|
+
|
|
|
+def _resolve_quality_mode(quality_mode: str) -> str:
|
|
|
+ normalized_mode = quality_mode.strip().lower()
|
|
|
+ if normalized_mode not in {"draft", "standard", "publication"}:
|
|
|
+ raise ValueError(f"Unsupported quality_mode: {quality_mode}")
|
|
|
+ return normalized_mode
|
|
|
+
|
|
|
+
|
|
|
+def _should_attempt_vision_review(*, quality_mode: str, review_enabled: bool, vision_review_mode: str) -> bool:
|
|
|
+ if not review_enabled or vision_review_mode == "off":
|
|
|
+ return False
|
|
|
+ if vision_review_mode == "on":
|
|
|
+ return quality_mode in {"standard", "publication"}
|
|
|
+ return quality_mode == "publication"
|
|
|
+
|
|
|
+
|
|
|
+def _default_max_reviews_for_mode(quality_mode: str) -> int:
|
|
|
+ mapping = {
|
|
|
+ "draft": 0,
|
|
|
+ "standard": 1,
|
|
|
+ "publication": 2,
|
|
|
+ }
|
|
|
+ return mapping[quality_mode]
|
|
|
+
|
|
|
+
|
|
|
+def _build_review_figures_dir(figures_root: Path, review_round: int) -> Path:
|
|
|
+ review_figures_dir = figures_root / f"review_round_{review_round}"
|
|
|
+ review_figures_dir.mkdir(parents=True, exist_ok=True)
|
|
|
+ return review_figures_dir
|
|
|
+
|
|
|
+
|
|
|
+def _serialize_step_traces(step_traces: tuple[AgentStepTrace, ...]) -> list[dict[str, Any]]:
|
|
|
+ return [asdict(trace) for trace in step_traces]
|
|
|
+
|
|
|
+
|
|
|
+def _reindex_step_traces(step_traces: list[AgentStepTrace], start_index: int) -> tuple[AgentStepTrace, ...]:
|
|
|
+ return tuple(
|
|
|
+ AgentStepTrace(
|
|
|
+ step_index=start_index + offset,
|
|
|
+ raw_response=trace.raw_response,
|
|
|
+ action=trace.action,
|
|
|
+ decision=trace.decision,
|
|
|
+ tool_name=trace.tool_name,
|
|
|
+ tool_status=trace.tool_status,
|
|
|
+ observation=trace.observation,
|
|
|
+ observation_preview=trace.observation_preview,
|
|
|
+ summary=trace.summary,
|
|
|
+ parse_error=trace.parse_error,
|
|
|
+ llm_duration_ms=trace.llm_duration_ms,
|
|
|
+ tool_duration_ms=trace.tool_duration_ms,
|
|
|
+ )
|
|
|
+ for offset, trace in enumerate(step_traces)
|
|
|
+ )
|
|
|
+
|
|
|
+
|
|
|
+def _serialize_analysis_rounds(rounds: tuple[AnalystRoundRecord, ...]) -> list[dict[str, Any]]:
|
|
|
+ return [
|
|
|
+ {
|
|
|
+ "round_index": round_record.round_index,
|
|
|
+ "report_path": round_record.report_path.as_posix(),
|
|
|
+ "step_traces": _serialize_step_traces(round_record.step_traces),
|
|
|
+ }
|
|
|
+ for round_record in rounds
|
|
|
+ ]
|
|
|
+
|
|
|
+
|
|
|
+def _serialize_review_history(review_history: tuple[ReviewRecord, ...]) -> list[dict[str, Any]]:
|
|
|
+ return [
|
|
|
+ {
|
|
|
+ "round_index": review.round_index,
|
|
|
+ "decision": review.decision,
|
|
|
+ "critique": review.critique,
|
|
|
+ "raw_response": review.raw_response,
|
|
|
+ "review_log_path": review.review_log_path.as_posix(),
|
|
|
+ "candidate_report_path": review.candidate_report_path.as_posix(),
|
|
|
+ }
|
|
|
+ for review in review_history
|
|
|
+ ]
|
|
|
+
|
|
|
+
|
|
|
+def _serialize_visual_review_history(visual_review_history: tuple[VisualReviewRecord, ...]) -> list[dict[str, Any]]:
|
|
|
+ return [
|
|
|
+ {
|
|
|
+ "round_index": review.round_index,
|
|
|
+ "status": review.status,
|
|
|
+ "decision": review.decision,
|
|
|
+ "summary": review.summary,
|
|
|
+ "figures_reviewed": list(review.figures_reviewed),
|
|
|
+ "skipped_figures": list(review.skipped_figures),
|
|
|
+ "duration_ms": review.duration_ms,
|
|
|
+ "raw_response": review.raw_response,
|
|
|
+ "warning": review.warning,
|
|
|
+ "log_path": review.log_path.as_posix(),
|
|
|
+ }
|
|
|
+ for review in visual_review_history
|
|
|
+ ]
|
|
|
+
|
|
|
+
|
|
|
+def _build_visual_review_summary(review: VisualReviewResult) -> str:
|
|
|
+ parts = [
|
|
|
+ f"- status: {review.status}",
|
|
|
+ f"- decision: {review.decision}",
|
|
|
+ f"- summary: {review.summary}",
|
|
|
+ ]
|
|
|
+ if review.figures_reviewed:
|
|
|
+ parts.append("- figures_reviewed:")
|
|
|
+ parts.extend(f" - {item}" for item in review.figures_reviewed)
|
|
|
+ if review.skipped_figures:
|
|
|
+ parts.append("- skipped_figures:")
|
|
|
+ parts.extend(f" - {item}" for item in review.skipped_figures)
|
|
|
+ if review.findings:
|
|
|
+ parts.append("- findings:")
|
|
|
+ for finding in review.findings:
|
|
|
+ parts.append(
|
|
|
+ f" - {finding.figure} | severity={finding.severity} | issue={finding.issue} | fix={finding.suggested_fix}"
|
|
|
+ )
|
|
|
+ return "\n".join(parts)
|
|
|
+
|
|
|
+
|
|
|
+def _build_reviewer_task(
|
|
|
+ *,
|
|
|
+ data_context: DataContextSummary,
|
|
|
+ report_markdown: str,
|
|
|
+ report_path: Path,
|
|
|
+ step_traces: tuple[AgentStepTrace, ...],
|
|
|
+ artifact_validation: ArtifactValidationResult,
|
|
|
+ telemetry: ReportTelemetry,
|
|
|
+ review_round: int,
|
|
|
+ visual_review_summary: str = "",
|
|
|
+) -> str:
|
|
|
+ trace_lines = []
|
|
|
+ for trace in step_traces:
|
|
|
+ trace_lines.append(
|
|
|
+ f"- Step {trace.step_index} | tool={trace.tool_name or 'finalize'} | "
|
|
|
+ f"status={trace.tool_status} | summary={trace.summary or trace.decision or 'n/a'}"
|
|
|
+ )
|
|
|
+ trace_summary = "\n".join(trace_lines) if trace_lines else "- No execution trace available."
|
|
|
+ missing = ", ".join(artifact_validation.missing_artifacts) if artifact_validation.missing_artifacts else "none"
|
|
|
+ warnings = "; ".join(artifact_validation.warnings) if artifact_validation.warnings else "none"
|
|
|
+ round_pattern = re.compile(rf"review_round_{review_round}(?:/|\\)")
|
|
|
+ round_figures = [
|
|
|
+ figure_path
|
|
|
+ for figure_path in telemetry.figures_generated
|
|
|
+ if round_pattern.search(str(figure_path))
|
|
|
+ ]
|
|
|
+ if not round_figures:
|
|
|
+ round_figures = list(telemetry.figures_generated)
|
|
|
+ figure_evidence_lines = []
|
|
|
+ for figure_path in round_figures:
|
|
|
+ figure_file = Path(figure_path)
|
|
|
+ figure_evidence_lines.append(
|
|
|
+ f"- {figure_file.name} | path={figure_file.as_posix()} | exists={figure_file.exists()}"
|
|
|
+ )
|
|
|
+ figures_block = "\n".join(figure_evidence_lines) if figure_evidence_lines else "- none"
|
|
|
+ figures_dir = report_path.parent / "figures" / f"review_round_{review_round}"
|
|
|
+ if not figures_dir.exists():
|
|
|
+ run_dir = report_path.parent
|
|
|
+ figures_dir = run_dir / "figures" / f"review_round_{review_round}"
|
|
|
+
|
|
|
+ return (
|
|
|
+ f"Review round: {review_round}\n"
|
|
|
+ f"Candidate report path: {report_path.as_posix()}\n\n"
|
|
|
+ "Dataset metadata summary:\n"
|
|
|
+ f"{data_context.context_text}\n"
|
|
|
+ "Execution trace summary:\n"
|
|
|
+ f"{trace_summary}\n\n"
|
|
|
+ "Generated artifacts evidence:\n"
|
|
|
+ f"- telemetry_figures_generated_count: {len(telemetry.figures_generated)}\n"
|
|
|
+ f"- review_round_figures_generated_count: {len(round_figures)}\n"
|
|
|
+ f"- review_round_figures_dir: {figures_dir.as_posix()}\n"
|
|
|
+ f"- review_round_figures_dir_exists: {figures_dir.exists()}\n"
|
|
|
+ f"- candidate_report_path: {report_path.as_posix()}\n"
|
|
|
+ f"- artifact_workflow_complete: {artifact_validation.workflow_complete}\n"
|
|
|
+ f"- artifact_missing_artifacts: {missing}\n"
|
|
|
+ f"- artifact_warnings: {warnings}\n"
|
|
|
+ "Generated figure list:\n"
|
|
|
+ f"{figures_block}\n\n"
|
|
|
+ + (
|
|
|
+ "Visual figure audit summary:\n"
|
|
|
+ f"{visual_review_summary}\n\n"
|
|
|
+ if visual_review_summary
|
|
|
+ else ""
|
|
|
+ )
|
|
|
+ + (
|
|
|
+ "Artifact validation summary:\n"
|
|
|
+ f"- workflow_complete: {artifact_validation.workflow_complete}\n"
|
|
|
+ f"- missing_artifacts: {missing}\n"
|
|
|
+ f"- warnings: {warnings}\n\n"
|
|
|
+ "Candidate final_report.md content:\n"
|
|
|
+ f"{report_markdown}"
|
|
|
+ )
|
|
|
+ )
|
|
|
+
|
|
|
+
|
|
|
+def _save_review_log(
|
|
|
+ *,
|
|
|
+ review_log_path: Path,
|
|
|
+ review_round: int,
|
|
|
+ reviewer_reply: ParsedReviewerReply,
|
|
|
+ candidate_report_path: Path,
|
|
|
+) -> Path:
|
|
|
+ payload = {
|
|
|
+ "round_index": review_round,
|
|
|
+ "decision": reviewer_reply.decision,
|
|
|
+ "critique": reviewer_reply.critique,
|
|
|
+ "raw_response": reviewer_reply.raw_response,
|
|
|
+ "candidate_report_path": candidate_report_path.as_posix(),
|
|
|
+ }
|
|
|
+ review_log_path.parent.mkdir(parents=True, exist_ok=True)
|
|
|
+ review_log_path.write_text(json.dumps(payload, ensure_ascii=False, indent=2), encoding="utf-8")
|
|
|
+ return review_log_path
|
|
|
+
|
|
|
+
|
|
|
+def _save_visual_review_log(
|
|
|
+ *,
|
|
|
+ review_log_path: Path,
|
|
|
+ review_round: int,
|
|
|
+ reviewer_reply: VisualReviewResult,
|
|
|
+) -> Path:
|
|
|
+ payload = {
|
|
|
+ "round_index": review_round,
|
|
|
+ "status": reviewer_reply.status,
|
|
|
+ "decision": reviewer_reply.decision,
|
|
|
+ "summary": reviewer_reply.summary,
|
|
|
+ "figures_reviewed": list(reviewer_reply.figures_reviewed),
|
|
|
+ "skipped_figures": list(reviewer_reply.skipped_figures),
|
|
|
+ "duration_ms": reviewer_reply.duration_ms,
|
|
|
+ "warning": reviewer_reply.warning,
|
|
|
+ "raw_response": reviewer_reply.raw_response,
|
|
|
+ "image_metadata": list(reviewer_reply.image_metadata),
|
|
|
+ "findings": [
|
|
|
+ {
|
|
|
+ "figure": finding.figure,
|
|
|
+ "severity": finding.severity,
|
|
|
+ "issue": finding.issue,
|
|
|
+ "suggested_fix": finding.suggested_fix,
|
|
|
+ }
|
|
|
+ for finding in reviewer_reply.findings
|
|
|
+ ],
|
|
|
+ }
|
|
|
+ review_log_path.parent.mkdir(parents=True, exist_ok=True)
|
|
|
+ review_log_path.write_text(json.dumps(payload, ensure_ascii=False, indent=2), encoding="utf-8")
|
|
|
+ return review_log_path
|
|
|
+
|
|
|
+
|
|
|
+def _save_agent_trace(
|
|
|
+ *,
|
|
|
+ trace_path: Path,
|
|
|
+ runtime_config: RuntimeConfig,
|
|
|
+ data_context: DataContextSummary,
|
|
|
+ run_dir: Path,
|
|
|
+ max_steps: int,
|
|
|
+ effective_max_steps: int,
|
|
|
+ step_traces: tuple[AgentStepTrace, ...],
|
|
|
+ telemetry: ReportTelemetry,
|
|
|
+ search_status: str,
|
|
|
+ search_notes: str,
|
|
|
+ tools_used: tuple[str, ...],
|
|
|
+ artifact_validation: ArtifactValidationResult,
|
|
|
+ analysis_rounds: tuple[AnalystRoundRecord, ...],
|
|
|
+ review_history: tuple[ReviewRecord, ...],
|
|
|
+ visual_review_history: tuple[VisualReviewRecord, ...],
|
|
|
+ document_ingestion: IngestionResult,
|
|
|
+ review_status: str,
|
|
|
+ quality_mode: str,
|
|
|
+ latency_mode: str,
|
|
|
+ vision_review_mode: str,
|
|
|
+ review_enabled: bool,
|
|
|
+ search_enabled: bool,
|
|
|
+ fast_path_enabled: bool,
|
|
|
+ small_simple_dataset: bool,
|
|
|
+ vision_configured: bool,
|
|
|
+ timing_breakdown: dict[str, int],
|
|
|
+) -> Path:
|
|
|
+ payload = {
|
|
|
+ "run_metadata": {
|
|
|
+ "timestamp": datetime.now().isoformat(timespec="seconds"),
|
|
|
+ "model_id": runtime_config.model_id,
|
|
|
+ "max_steps": max_steps,
|
|
|
+ "effective_max_steps": effective_max_steps,
|
|
|
+ "data_path": data_context.absolute_path.as_posix(),
|
|
|
+ "input_kind": document_ingestion.input_kind,
|
|
|
+ "run_dir": run_dir.as_posix(),
|
|
|
+ "quality_mode": quality_mode,
|
|
|
+ "latency_mode": latency_mode,
|
|
|
+ "vision_review_mode": vision_review_mode,
|
|
|
+ "review_enabled": review_enabled,
|
|
|
+ "search_enabled": search_enabled,
|
|
|
+ "fast_path_enabled": fast_path_enabled,
|
|
|
+ "small_simple_dataset": small_simple_dataset,
|
|
|
+ "vision_configured": vision_configured,
|
|
|
+ },
|
|
|
+ "step_traces": _serialize_step_traces(step_traces),
|
|
|
+ "analysis_rounds": _serialize_analysis_rounds(analysis_rounds),
|
|
|
+ "review_history": _serialize_review_history(review_history),
|
|
|
+ "vision_review_history": _serialize_visual_review_history(visual_review_history),
|
|
|
+ "document_ingestion": {
|
|
|
+ "input_kind": document_ingestion.input_kind,
|
|
|
+ "status": document_ingestion.status,
|
|
|
+ "summary": document_ingestion.summary,
|
|
|
+ "normalized_data_path": document_ingestion.normalized_data_path.as_posix(),
|
|
|
+ "duration_ms": document_ingestion.duration_ms,
|
|
|
+ "log_path": document_ingestion.log_path.as_posix() if document_ingestion.log_path else None,
|
|
|
+ "parsed_document_path": (
|
|
|
+ document_ingestion.parsed_document_path.as_posix()
|
|
|
+ if document_ingestion.parsed_document_path
|
|
|
+ else None
|
|
|
+ ),
|
|
|
+ "selected_table_id": document_ingestion.selected_table_id,
|
|
|
+ "candidate_table_count": document_ingestion.candidate_table_count,
|
|
|
+ "selected_table_shape": list(document_ingestion.selected_table_shape)
|
|
|
+ if document_ingestion.selected_table_shape
|
|
|
+ else None,
|
|
|
+ "selected_table_headers": list(document_ingestion.selected_table_headers),
|
|
|
+ "selected_table_numeric_columns": list(document_ingestion.selected_table_numeric_columns),
|
|
|
+ "candidate_table_summaries": list(document_ingestion.candidate_table_summaries),
|
|
|
+ "pdf_multi_table_mode": document_ingestion.pdf_multi_table_mode,
|
|
|
+ "warnings": list(document_ingestion.warnings),
|
|
|
+ },
|
|
|
+ "telemetry": {
|
|
|
+ "methods": list(telemetry.methods),
|
|
|
+ "domain": telemetry.domain,
|
|
|
+ "tools_used": list(tools_used),
|
|
|
+ "search_used": telemetry.search_used,
|
|
|
+ "search_notes": search_notes,
|
|
|
+ "cleaned_data_saved": telemetry.cleaned_data_saved,
|
|
|
+ "cleaned_data_path": telemetry.cleaned_data_path,
|
|
|
+ "figures_generated": list(telemetry.figures_generated),
|
|
|
+ "telemetry_valid": telemetry.valid,
|
|
|
+ "telemetry_warning": telemetry.warning,
|
|
|
+ },
|
|
|
+ "artifact_validation": {
|
|
|
+ "workflow_complete": artifact_validation.workflow_complete,
|
|
|
+ "missing_artifacts": list(artifact_validation.missing_artifacts),
|
|
|
+ "warnings": list(artifact_validation.warnings),
|
|
|
+ "cleaned_data_exists": artifact_validation.cleaned_data_exists,
|
|
|
+ "report_exists": artifact_validation.report_exists,
|
|
|
+ "trace_exists": artifact_validation.trace_exists,
|
|
|
+ },
|
|
|
+ "search_status": search_status,
|
|
|
+ "review_status": review_status,
|
|
|
+ "timing_breakdown": dict(timing_breakdown),
|
|
|
+ }
|
|
|
+ trace_path.parent.mkdir(parents=True, exist_ok=True)
|
|
|
+ trace_path.write_text(json.dumps(payload, ensure_ascii=False, indent=2), encoding="utf-8")
|
|
|
+ return trace_path
|
|
|
+
|
|
|
+
|
|
|
+def _validate_artifacts(
|
|
|
+ *,
|
|
|
+ cleaned_data_path: Path,
|
|
|
+ report_path: Path,
|
|
|
+ trace_path: Path,
|
|
|
+ telemetry: ReportTelemetry,
|
|
|
+) -> ArtifactValidationResult:
|
|
|
+ missing_artifacts: list[str] = []
|
|
|
+ warnings: list[str] = []
|
|
|
+
|
|
|
+ cleaned_data_exists = cleaned_data_path.exists()
|
|
|
+ report_exists = report_path.exists()
|
|
|
+ trace_exists = trace_path.exists()
|
|
|
+
|
|
|
+ if not cleaned_data_exists:
|
|
|
+ missing_artifacts.append(cleaned_data_path.as_posix())
|
|
|
+ if not report_exists:
|
|
|
+ missing_artifacts.append(report_path.as_posix())
|
|
|
+ if not trace_exists:
|
|
|
+ missing_artifacts.append(trace_path.as_posix())
|
|
|
+
|
|
|
+ if telemetry.cleaned_data_saved and not cleaned_data_exists:
|
|
|
+ warnings.append("Telemetry claimed cleaned_data_saved=true, but cleaned_data.csv was not found on disk.")
|
|
|
+ if telemetry.cleaned_data_path and telemetry.cleaned_data_path != cleaned_data_path.as_posix():
|
|
|
+ warnings.append("Telemetry cleaned_data_path does not match the required production path.")
|
|
|
+
|
|
|
+ workflow_complete = not missing_artifacts
|
|
|
+ if not workflow_complete:
|
|
|
+ warnings.append("This run did not complete the production-grade artifact contract.")
|
|
|
+
|
|
|
+ return ArtifactValidationResult(
|
|
|
+ workflow_complete=workflow_complete,
|
|
|
+ missing_artifacts=tuple(missing_artifacts),
|
|
|
+ warnings=tuple(warnings),
|
|
|
+ cleaned_data_exists=cleaned_data_exists,
|
|
|
+ report_exists=report_exists,
|
|
|
+ trace_exists=trace_exists,
|
|
|
+ )
|
|
|
+
|
|
|
+
|
|
|
+class ScientificReActRunner:
|
|
|
+ """Custom JSON-driven ReAct controller for scientific analysis tasks."""
|
|
|
+
|
|
|
+ def __init__(
|
|
|
+ self,
|
|
|
+ *,
|
|
|
+ name: str,
|
|
|
+ llm: Any,
|
|
|
+ system_prompt: str,
|
|
|
+ tool_registry: Any,
|
|
|
+ max_steps: int = 6,
|
|
|
+ fast_path_enabled: bool = False,
|
|
|
+ event_handler: Optional[EventHandler] = None,
|
|
|
+ ) -> None:
|
|
|
+ self.name = name
|
|
|
+ self.llm = llm
|
|
|
+ self.system_prompt = system_prompt
|
|
|
+ self.tool_registry = tool_registry
|
|
|
+ self.max_steps = max_steps
|
|
|
+ self.fast_path_enabled = fast_path_enabled
|
|
|
+ self.event_handler = event_handler
|
|
|
+
|
|
|
+ def build_initial_messages(self, user_task: str) -> list[dict[str, str]]:
|
|
|
+ return [
|
|
|
+ {"role": "system", "content": self.system_prompt},
|
|
|
+ {"role": "user", "content": user_task},
|
|
|
+ ]
|
|
|
+
|
|
|
+ def run(self, user_task: str) -> tuple[str, list[AgentStepTrace]]:
|
|
|
+ final_answer, traces, _ = self.run_with_messages(self.build_initial_messages(user_task))
|
|
|
+ return final_answer, traces
|
|
|
+
|
|
|
+ def run_with_messages(
|
|
|
+ self,
|
|
|
+ messages: list[dict[str, str]],
|
|
|
+ *,
|
|
|
+ analysis_round: int = 1,
|
|
|
+ ) -> tuple[str, list[AgentStepTrace], list[dict[str, str]]]:
|
|
|
+ messages = list(messages)
|
|
|
+ traces: list[AgentStepTrace] = []
|
|
|
+ available_tools = set(self.tool_registry.list_tools())
|
|
|
+
|
|
|
+ _emit_event(
|
|
|
+ self.event_handler,
|
|
|
+ "analysis_started",
|
|
|
+ agent_name=self.name,
|
|
|
+ max_steps=self.max_steps,
|
|
|
+ analysis_round=analysis_round,
|
|
|
+ )
|
|
|
+
|
|
|
+ for step_index in range(1, self.max_steps + 1):
|
|
|
+ _emit_event(self.event_handler, "step_started", step_index=step_index, max_steps=self.max_steps)
|
|
|
+ llm_started_at = time.perf_counter()
|
|
|
+ raw_response = str(self.llm.invoke(messages)).strip()
|
|
|
+ llm_duration_ms = _elapsed_ms(llm_started_at)
|
|
|
+
|
|
|
+ try:
|
|
|
+ reply = _parse_agent_reply(raw_response)
|
|
|
+ except ValueError as exc:
|
|
|
+ parse_error = str(exc)
|
|
|
+ trace = AgentStepTrace(
|
|
|
+ step_index=step_index,
|
|
|
+ raw_response=raw_response,
|
|
|
+ action="parse_error",
|
|
|
+ tool_status="error",
|
|
|
+ summary=f"Model response failed JSON validation: {parse_error}",
|
|
|
+ parse_error=parse_error,
|
|
|
+ llm_duration_ms=llm_duration_ms,
|
|
|
+ )
|
|
|
+ traces.append(trace)
|
|
|
+ _emit_event(
|
|
|
+ self.event_handler,
|
|
|
+ "step_parse_error",
|
|
|
+ step_index=step_index,
|
|
|
+ message=parse_error,
|
|
|
+ )
|
|
|
+ messages.append({"role": "assistant", "content": raw_response})
|
|
|
+ messages.append({"role": "user", "content": build_response_format_feedback(parse_error)})
|
|
|
+ continue
|
|
|
+
|
|
|
+ if reply.action == "call_tool":
|
|
|
+ _emit_event(
|
|
|
+ self.event_handler,
|
|
|
+ "tool_call_started",
|
|
|
+ step_index=step_index,
|
|
|
+ tool_name=reply.tool_name,
|
|
|
+ decision=reply.decision,
|
|
|
+ )
|
|
|
+
|
|
|
+ if reply.tool_name not in available_tools:
|
|
|
+ observation = json.dumps(
|
|
|
+ {
|
|
|
+ "status": "error",
|
|
|
+ "text": f"Tool '{reply.tool_name}' is not registered.",
|
|
|
+ "available_tools": sorted(available_tools),
|
|
|
+ },
|
|
|
+ ensure_ascii=False,
|
|
|
+ indent=2,
|
|
|
+ )
|
|
|
+ tool_duration_ms = 0
|
|
|
+ else:
|
|
|
+ tool_started_at = time.perf_counter()
|
|
|
+ observation = self.tool_registry.execute_tool(reply.tool_name, reply.tool_input)
|
|
|
+ tool_duration_ms = _elapsed_ms(tool_started_at)
|
|
|
+
|
|
|
+ tool_status, observation_preview = _parse_tool_observation(observation)
|
|
|
+ observation_summary = _build_observation_summary(
|
|
|
+ tool_name=reply.tool_name,
|
|
|
+ observation=observation,
|
|
|
+ tool_status=tool_status,
|
|
|
+ observation_preview=observation_preview,
|
|
|
+ )
|
|
|
+ trace = AgentStepTrace(
|
|
|
+ step_index=step_index,
|
|
|
+ raw_response=raw_response,
|
|
|
+ action=reply.action,
|
|
|
+ decision=reply.decision,
|
|
|
+ tool_name=reply.tool_name,
|
|
|
+ tool_status=tool_status,
|
|
|
+ observation=observation,
|
|
|
+ observation_preview=observation_preview,
|
|
|
+ summary=_build_step_summary(reply.tool_name, reply.decision, tool_status, observation_preview),
|
|
|
+ llm_duration_ms=llm_duration_ms,
|
|
|
+ tool_duration_ms=tool_duration_ms,
|
|
|
+ )
|
|
|
+ traces.append(trace)
|
|
|
+
|
|
|
+ _emit_event(
|
|
|
+ self.event_handler,
|
|
|
+ "tool_call_completed",
|
|
|
+ step_index=step_index,
|
|
|
+ tool_name=reply.tool_name,
|
|
|
+ decision=reply.decision,
|
|
|
+ tool_status=tool_status,
|
|
|
+ observation_preview=observation_preview,
|
|
|
+ summary=trace.summary,
|
|
|
+ llm_duration_ms=llm_duration_ms,
|
|
|
+ tool_duration_ms=tool_duration_ms,
|
|
|
+ )
|
|
|
+
|
|
|
+ messages.append({"role": "assistant", "content": raw_response})
|
|
|
+ messages.append(
|
|
|
+ {
|
|
|
+ "role": "user",
|
|
|
+ "content": build_observation_prompt(
|
|
|
+ tool_name=reply.tool_name,
|
|
|
+ observation_summary=observation_summary,
|
|
|
+ remaining_steps=self.max_steps - step_index,
|
|
|
+ fast_path_enabled=self.fast_path_enabled,
|
|
|
+ ),
|
|
|
+ }
|
|
|
+ )
|
|
|
+ continue
|
|
|
+
|
|
|
+ trace = AgentStepTrace(
|
|
|
+ step_index=step_index,
|
|
|
+ raw_response=raw_response,
|
|
|
+ action=reply.action,
|
|
|
+ decision=reply.decision,
|
|
|
+ tool_status="success",
|
|
|
+ summary=f"Generated final Markdown report: {reply.decision or 'analysis complete'}",
|
|
|
+ llm_duration_ms=llm_duration_ms,
|
|
|
+ )
|
|
|
+ traces.append(trace)
|
|
|
+ _emit_event(
|
|
|
+ self.event_handler,
|
|
|
+ "analysis_finished",
|
|
|
+ step_index=step_index,
|
|
|
+ decision=reply.decision,
|
|
|
+ )
|
|
|
+ messages.append({"role": "assistant", "content": raw_response})
|
|
|
+ return reply.final_answer, traces, messages
|
|
|
+
|
|
|
+ fallback_report = (
|
|
|
+ "# Data Analysis Report\n\n"
|
|
|
+ "The agent reached the maximum number of reasoning steps before producing a final report.\n\n"
|
|
|
+ "## Next Action\n"
|
|
|
+ "Please review the step traces to identify whether the issue came from response formatting, "
|
|
|
+ "tool execution errors, or insufficient statistical instructions.\n\n"
|
|
|
+ "<telemetry>{\"methods\": [], \"domain\": \"unknown\", \"tools_used\": [], "
|
|
|
+ "\"search_used\": false, \"search_notes\": \"Agent reached max steps before finalizing.\", "
|
|
|
+ "\"cleaned_data_saved\": false, \"cleaned_data_path\": \"\", \"figures_generated\": []}</telemetry>"
|
|
|
+ )
|
|
|
+ _emit_event(self.event_handler, "analysis_max_steps", max_steps=self.max_steps)
|
|
|
+ return fallback_report, traces, messages
|
|
|
+
|
|
|
+
|
|
|
+def run_analysis(
|
|
|
+ data_path: str | Path,
|
|
|
+ *,
|
|
|
+ query: str = DEFAULT_QUERY,
|
|
|
+ output_dir: str | Path = "outputs",
|
|
|
+ report_path: Optional[str | Path] = None,
|
|
|
+ env_file: Optional[str | Path] = None,
|
|
|
+ agent_name: str = "Advanced Data Analyst",
|
|
|
+ max_steps: int = 6,
|
|
|
+ max_reviews: Optional[int] = None,
|
|
|
+ quality_mode: str = "standard",
|
|
|
+ latency_mode: str = "auto",
|
|
|
+ document_ingestion_mode: str = "auto",
|
|
|
+ max_pdf_pages: int = 20,
|
|
|
+ max_candidate_tables: int = 5,
|
|
|
+ selected_table_id: str | None = None,
|
|
|
+ vision_review_mode: str = "auto",
|
|
|
+ vision_max_images: int = 3,
|
|
|
+ vision_max_image_side: int = 1024,
|
|
|
+ event_handler: Optional[EventHandler] = None,
|
|
|
+ verbose: bool = False,
|
|
|
+) -> AnalysisRunResult:
|
|
|
+ """Run the full data analysis workflow."""
|
|
|
+
|
|
|
+ if event_handler is None and verbose:
|
|
|
+ event_handler = build_plaintext_event_handler()
|
|
|
+
|
|
|
+ run_started_at = time.perf_counter()
|
|
|
+ timing_breakdown: dict[str, int] = {}
|
|
|
+
|
|
|
+ _emit_event(event_handler, "config_loading")
|
|
|
+ config_started_at = time.perf_counter()
|
|
|
+ runtime_config: RuntimeConfig = load_runtime_config(env_file=env_file)
|
|
|
+ _accumulate_duration(timing_breakdown, "config_load_duration_ms", _elapsed_ms(config_started_at))
|
|
|
+
|
|
|
+ resolved_quality_mode = _resolve_quality_mode(quality_mode)
|
|
|
+ resolved_latency_mode = _resolve_latency_mode(latency_mode)
|
|
|
+ resolved_vision_review_mode = _resolve_vision_review_mode(vision_review_mode)
|
|
|
+ review_enabled = resolved_quality_mode != "draft"
|
|
|
+ effective_max_reviews = (
|
|
|
+ _default_max_reviews_for_mode(resolved_quality_mode) if max_reviews is None else max(0, max_reviews)
|
|
|
+ )
|
|
|
+ if not review_enabled:
|
|
|
+ effective_max_reviews = 0
|
|
|
+
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "config_loaded",
|
|
|
+ tavily_configured=bool(runtime_config.tavily_api_key),
|
|
|
+ vision_configured=runtime_config.vision_configured,
|
|
|
+ model_id=runtime_config.model_id,
|
|
|
+ latency_mode=resolved_latency_mode,
|
|
|
+ search_enabled=bool(runtime_config.tavily_api_key),
|
|
|
+ )
|
|
|
+
|
|
|
+ run_dir, data_dir, figures_dir, logs_dir = _create_run_directory(output_dir)
|
|
|
+ cleaned_data_path = data_dir / "cleaned_data.csv"
|
|
|
+ final_report_path = run_dir / "final_report.md"
|
|
|
+ trace_path = logs_dir / "agent_trace.json"
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "run_directory_created",
|
|
|
+ run_dir=run_dir.as_posix(),
|
|
|
+ data_dir=data_dir.as_posix(),
|
|
|
+ figures_dir=figures_dir.as_posix(),
|
|
|
+ logs_dir=logs_dir.as_posix(),
|
|
|
+ )
|
|
|
+
|
|
|
+ source_path = Path(data_path).resolve()
|
|
|
+ input_kind = "pdf" if source_path.suffix.lower() == ".pdf" else "tabular"
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "document_ingestion_started",
|
|
|
+ input_kind=input_kind,
|
|
|
+ data_path=source_path.as_posix(),
|
|
|
+ )
|
|
|
+ ingestion_started_at = time.perf_counter()
|
|
|
+ document_ingestion = ingest_input_document(
|
|
|
+ source_path,
|
|
|
+ run_dir=run_dir,
|
|
|
+ data_dir=data_dir,
|
|
|
+ logs_dir=logs_dir,
|
|
|
+ mode=document_ingestion_mode,
|
|
|
+ max_pdf_pages=max_pdf_pages,
|
|
|
+ max_candidate_tables=max_candidate_tables,
|
|
|
+ selected_table_id=selected_table_id,
|
|
|
+ )
|
|
|
+ _accumulate_duration(
|
|
|
+ timing_breakdown,
|
|
|
+ "document_ingestion_duration_ms",
|
|
|
+ max(document_ingestion.duration_ms, _elapsed_ms(ingestion_started_at)),
|
|
|
+ )
|
|
|
+ if document_ingestion.status == "not_needed":
|
|
|
+ _emit_event(event_handler, "document_ingestion_skipped")
|
|
|
+ else:
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "document_ingestion_completed",
|
|
|
+ status=document_ingestion.status,
|
|
|
+ summary=document_ingestion.summary,
|
|
|
+ input_kind=document_ingestion.input_kind,
|
|
|
+ )
|
|
|
+ if document_ingestion.status == "failed":
|
|
|
+ raise ValueError(document_ingestion.summary)
|
|
|
+
|
|
|
+ _emit_event(event_handler, "data_context_loading", data_path=document_ingestion.normalized_data_path.as_posix())
|
|
|
+ data_context_started_at = time.perf_counter()
|
|
|
+ data_context = build_data_context(
|
|
|
+ document_ingestion.normalized_data_path,
|
|
|
+ input_kind=document_ingestion.input_kind,
|
|
|
+ parsed_document_path=document_ingestion.parsed_document_path,
|
|
|
+ )
|
|
|
+ _accumulate_duration(timing_breakdown, "data_context_duration_ms", _elapsed_ms(data_context_started_at))
|
|
|
+ small_simple_dataset = _is_small_simple_dataset(data_context)
|
|
|
+ fast_path_enabled = _should_use_fast_path(resolved_latency_mode, small_simple_dataset=small_simple_dataset)
|
|
|
+ effective_max_steps = _resolve_effective_max_steps(
|
|
|
+ requested_max_steps=max_steps,
|
|
|
+ quality_mode=resolved_quality_mode,
|
|
|
+ latency_mode=resolved_latency_mode,
|
|
|
+ small_simple_dataset=small_simple_dataset,
|
|
|
+ )
|
|
|
+ search_enabled = _should_enable_search(
|
|
|
+ runtime_config=runtime_config,
|
|
|
+ data_context=data_context,
|
|
|
+ query=query,
|
|
|
+ quality_mode=resolved_quality_mode,
|
|
|
+ latency_mode=resolved_latency_mode,
|
|
|
+ )
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "data_context_ready",
|
|
|
+ data_path=data_context.absolute_path.as_posix(),
|
|
|
+ shape=data_context.shape,
|
|
|
+ columns=data_context.columns,
|
|
|
+ small_simple_dataset=small_simple_dataset,
|
|
|
+ )
|
|
|
+
|
|
|
+ tool_registry = build_tool_registry(enable_search=search_enabled)
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "tool_registry_ready",
|
|
|
+ tools=tool_registry.list_tools(),
|
|
|
+ search_enabled=search_enabled,
|
|
|
+ fast_path_enabled=fast_path_enabled,
|
|
|
+ effective_max_steps=effective_max_steps,
|
|
|
+ )
|
|
|
+
|
|
|
+ llm = build_llm(runtime_config)
|
|
|
+ all_step_traces: list[AgentStepTrace] = []
|
|
|
+ analysis_rounds: list[AnalystRoundRecord] = []
|
|
|
+ review_history: list[ReviewRecord] = []
|
|
|
+ visual_review_history: list[VisualReviewRecord] = []
|
|
|
+
|
|
|
+ raw_result = ""
|
|
|
+ report_markdown = ""
|
|
|
+ telemetry = ReportTelemetry()
|
|
|
+ search_status = "not_used"
|
|
|
+ search_notes = "No online knowledge retrieval was triggered."
|
|
|
+ tools_used: tuple[str, ...] = ()
|
|
|
+ artifact_validation = ArtifactValidationResult(
|
|
|
+ workflow_complete=False,
|
|
|
+ missing_artifacts=(),
|
|
|
+ warnings=(),
|
|
|
+ cleaned_data_exists=False,
|
|
|
+ report_exists=False,
|
|
|
+ trace_exists=False,
|
|
|
+ )
|
|
|
+ review_status = "skipped" if not review_enabled else "rejected"
|
|
|
+ review_critique = ""
|
|
|
+ review_rounds_used = 0
|
|
|
+ vision_review_status = "skipped"
|
|
|
+ vision_review_summary = ""
|
|
|
+ visual_attempt_enabled = False
|
|
|
+ saved_report_path = final_report_path
|
|
|
+ saved_trace_path = trace_path
|
|
|
+ analyst_messages: list[dict[str, str]] | None = None
|
|
|
+ current_runner: Optional[ScientificReActRunner] = None
|
|
|
+
|
|
|
+ total_rounds = 1 if not review_enabled else 1 + effective_max_reviews
|
|
|
+
|
|
|
+ for review_round in range(1, total_rounds + 1):
|
|
|
+ review_figures_dir = _build_review_figures_dir(figures_dir, review_round)
|
|
|
+ system_prompt = build_system_prompt(
|
|
|
+ run_dir=run_dir.as_posix(),
|
|
|
+ cleaned_data_path=cleaned_data_path.as_posix(),
|
|
|
+ figures_dir=review_figures_dir.as_posix(),
|
|
|
+ logs_dir=logs_dir.as_posix(),
|
|
|
+ background_literature_context=data_context.background_literature_context,
|
|
|
+ max_steps=effective_max_steps,
|
|
|
+ tool_descriptions=tool_registry.get_tools_description(),
|
|
|
+ search_enabled=search_enabled,
|
|
|
+ latency_mode=resolved_latency_mode,
|
|
|
+ fast_path_enabled=fast_path_enabled,
|
|
|
+ pdf_small_table_mode=data_context.pdf_small_table_mode,
|
|
|
+ )
|
|
|
+ current_runner = ScientificReActRunner(
|
|
|
+ name=agent_name,
|
|
|
+ llm=llm,
|
|
|
+ system_prompt=system_prompt,
|
|
|
+ tool_registry=tool_registry,
|
|
|
+ max_steps=effective_max_steps,
|
|
|
+ fast_path_enabled=fast_path_enabled,
|
|
|
+ event_handler=event_handler,
|
|
|
+ )
|
|
|
+ run_context_text = _build_run_context_text(run_dir, cleaned_data_path, review_figures_dir, logs_dir)
|
|
|
+ if analyst_messages is None:
|
|
|
+ analyst_messages = current_runner.build_initial_messages(
|
|
|
+ f"{query}\n{data_context.context_text}\n{run_context_text}"
|
|
|
+ )
|
|
|
+ else:
|
|
|
+ analyst_messages[0] = {"role": "system", "content": system_prompt}
|
|
|
+
|
|
|
+ raw_result, round_traces, analyst_messages = current_runner.run_with_messages(
|
|
|
+ analyst_messages,
|
|
|
+ analysis_round=review_round,
|
|
|
+ )
|
|
|
+ _accumulate_duration(
|
|
|
+ timing_breakdown,
|
|
|
+ "llm_duration_ms",
|
|
|
+ sum(trace.llm_duration_ms for trace in round_traces),
|
|
|
+ )
|
|
|
+ _accumulate_duration(
|
|
|
+ timing_breakdown,
|
|
|
+ "tool_duration_ms",
|
|
|
+ sum(trace.tool_duration_ms for trace in round_traces),
|
|
|
+ )
|
|
|
+ _accumulate_duration(
|
|
|
+ timing_breakdown,
|
|
|
+ "tavily_duration_ms",
|
|
|
+ sum(trace.tool_duration_ms for trace in round_traces if trace.tool_name == "TavilySearchTool"),
|
|
|
+ )
|
|
|
+ reindexed_traces = _reindex_step_traces(round_traces, start_index=len(all_step_traces) + 1)
|
|
|
+ all_step_traces.extend(reindexed_traces)
|
|
|
+
|
|
|
+ extraction = extract_report_and_telemetry(raw_result)
|
|
|
+ report_markdown = extraction.report_markdown
|
|
|
+ telemetry = extraction.telemetry
|
|
|
+
|
|
|
+ round_report_path = run_dir / f"review_round_{review_round}_report.md"
|
|
|
+ analysis_rounds.append(
|
|
|
+ AnalystRoundRecord(
|
|
|
+ round_index=review_round,
|
|
|
+ report_path=round_report_path,
|
|
|
+ step_traces=reindexed_traces,
|
|
|
+ )
|
|
|
+ )
|
|
|
+
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "report_persisting",
|
|
|
+ report_path=final_report_path.as_posix(),
|
|
|
+ trace_path=trace_path.as_posix(),
|
|
|
+ review_round=review_round,
|
|
|
+ )
|
|
|
+ report_persist_started_at = time.perf_counter()
|
|
|
+ saved_report_path = save_markdown_report(report_markdown, final_report_path)
|
|
|
+ save_markdown_report(report_markdown, round_report_path)
|
|
|
+ _accumulate_duration(timing_breakdown, "report_persist_duration_ms", _elapsed_ms(report_persist_started_at))
|
|
|
+
|
|
|
+ step_traces_tuple = tuple(all_step_traces)
|
|
|
+ tools_used = _collect_tools_used(step_traces_tuple, telemetry)
|
|
|
+ search_status, search_notes = _determine_search_status(step_traces_tuple, telemetry)
|
|
|
+
|
|
|
+ initial_validation = ArtifactValidationResult(
|
|
|
+ workflow_complete=False,
|
|
|
+ missing_artifacts=(),
|
|
|
+ warnings=(),
|
|
|
+ cleaned_data_exists=cleaned_data_path.exists(),
|
|
|
+ report_exists=saved_report_path.exists(),
|
|
|
+ trace_exists=False,
|
|
|
+ )
|
|
|
+ trace_persist_started_at = time.perf_counter()
|
|
|
+ saved_trace_path = _save_agent_trace(
|
|
|
+ trace_path=trace_path,
|
|
|
+ runtime_config=runtime_config,
|
|
|
+ data_context=data_context,
|
|
|
+ run_dir=run_dir,
|
|
|
+ max_steps=max_steps,
|
|
|
+ effective_max_steps=effective_max_steps,
|
|
|
+ step_traces=step_traces_tuple,
|
|
|
+ telemetry=telemetry,
|
|
|
+ search_status=search_status,
|
|
|
+ search_notes=search_notes,
|
|
|
+ tools_used=tools_used,
|
|
|
+ artifact_validation=initial_validation,
|
|
|
+ analysis_rounds=tuple(analysis_rounds),
|
|
|
+ review_history=tuple(review_history),
|
|
|
+ visual_review_history=tuple(visual_review_history),
|
|
|
+ document_ingestion=document_ingestion,
|
|
|
+ review_status=review_status,
|
|
|
+ quality_mode=resolved_quality_mode,
|
|
|
+ latency_mode=resolved_latency_mode,
|
|
|
+ vision_review_mode=resolved_vision_review_mode,
|
|
|
+ review_enabled=review_enabled,
|
|
|
+ search_enabled=search_enabled,
|
|
|
+ fast_path_enabled=fast_path_enabled,
|
|
|
+ small_simple_dataset=small_simple_dataset,
|
|
|
+ vision_configured=runtime_config.vision_configured,
|
|
|
+ timing_breakdown=dict(timing_breakdown),
|
|
|
+ )
|
|
|
+ _accumulate_duration(timing_breakdown, "trace_persist_duration_ms", _elapsed_ms(trace_persist_started_at))
|
|
|
+
|
|
|
+ artifact_validation = _validate_artifacts(
|
|
|
+ cleaned_data_path=cleaned_data_path,
|
|
|
+ report_path=saved_report_path,
|
|
|
+ trace_path=saved_trace_path,
|
|
|
+ telemetry=telemetry,
|
|
|
+ )
|
|
|
+
|
|
|
+ if not review_enabled:
|
|
|
+ review_status = "skipped"
|
|
|
+ review_rounds_used = 0
|
|
|
+ review_critique = "Review skipped in draft mode."
|
|
|
+ break
|
|
|
+
|
|
|
+ visual_attempt_enabled = _should_attempt_vision_review(
|
|
|
+ quality_mode=resolved_quality_mode,
|
|
|
+ review_enabled=review_enabled,
|
|
|
+ vision_review_mode=resolved_vision_review_mode,
|
|
|
+ )
|
|
|
+ visual_review_log_path = logs_dir / f"review_round_{review_round}_visual_review.json"
|
|
|
+ if visual_attempt_enabled:
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "vision_review_started",
|
|
|
+ review_round=review_round,
|
|
|
+ report_path=saved_report_path.as_posix(),
|
|
|
+ )
|
|
|
+ visual_review_result = run_visual_review(
|
|
|
+ runtime_config=runtime_config,
|
|
|
+ report_markdown=report_markdown,
|
|
|
+ telemetry=telemetry,
|
|
|
+ run_dir=run_dir,
|
|
|
+ review_round=review_round,
|
|
|
+ max_images=max(1, int(vision_max_images)),
|
|
|
+ max_image_side=max(256, min(int(vision_max_image_side), 2048)),
|
|
|
+ )
|
|
|
+ else:
|
|
|
+ visual_review_result = VisualReviewResult(
|
|
|
+ status="skipped",
|
|
|
+ decision="Skipped",
|
|
|
+ summary="当前质量档位与视觉审稿模式组合未启用视觉审稿。",
|
|
|
+ )
|
|
|
+
|
|
|
+ if visual_review_result.duration_ms:
|
|
|
+ _accumulate_duration(timing_breakdown, "vision_review_duration_ms", visual_review_result.duration_ms)
|
|
|
+ vision_review_status = visual_review_result.status
|
|
|
+ vision_review_summary = visual_review_result.summary
|
|
|
+ saved_visual_review_log_path = _save_visual_review_log(
|
|
|
+ review_log_path=visual_review_log_path,
|
|
|
+ review_round=review_round,
|
|
|
+ reviewer_reply=visual_review_result,
|
|
|
+ )
|
|
|
+ visual_review_history.append(
|
|
|
+ VisualReviewRecord(
|
|
|
+ round_index=review_round,
|
|
|
+ status=visual_review_result.status,
|
|
|
+ decision=visual_review_result.decision,
|
|
|
+ summary=visual_review_result.summary,
|
|
|
+ figures_reviewed=visual_review_result.figures_reviewed,
|
|
|
+ skipped_figures=visual_review_result.skipped_figures,
|
|
|
+ duration_ms=visual_review_result.duration_ms,
|
|
|
+ raw_response=visual_review_result.raw_response,
|
|
|
+ warning=visual_review_result.warning,
|
|
|
+ log_path=saved_visual_review_log_path,
|
|
|
+ )
|
|
|
+ )
|
|
|
+ if visual_review_result.status == "completed":
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "vision_review_completed",
|
|
|
+ review_round=review_round,
|
|
|
+ status=visual_review_result.status,
|
|
|
+ decision=visual_review_result.decision,
|
|
|
+ summary=visual_review_result.summary,
|
|
|
+ )
|
|
|
+ else:
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "vision_review_skipped",
|
|
|
+ review_round=review_round,
|
|
|
+ reason=visual_review_result.summary,
|
|
|
+ status=visual_review_result.status,
|
|
|
+ )
|
|
|
+
|
|
|
+ reviewer_messages = [
|
|
|
+ {
|
|
|
+ "role": "system",
|
|
|
+ "content": build_reviewer_prompt(
|
|
|
+ resolved_quality_mode,
|
|
|
+ focus_major_issues=(
|
|
|
+ fast_path_enabled
|
|
|
+ and resolved_quality_mode == "standard"
|
|
|
+ and artifact_validation.workflow_complete
|
|
|
+ and not any(trace.tool_status == "error" or trace.parse_error for trace in reindexed_traces)
|
|
|
+ ),
|
|
|
+ ),
|
|
|
+ },
|
|
|
+ {
|
|
|
+ "role": "user",
|
|
|
+ "content": _build_reviewer_task(
|
|
|
+ data_context=data_context,
|
|
|
+ report_markdown=report_markdown,
|
|
|
+ report_path=saved_report_path,
|
|
|
+ step_traces=reindexed_traces,
|
|
|
+ artifact_validation=artifact_validation,
|
|
|
+ telemetry=telemetry,
|
|
|
+ review_round=review_round,
|
|
|
+ visual_review_summary=_build_visual_review_summary(visual_review_result),
|
|
|
+ ),
|
|
|
+ },
|
|
|
+ ]
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "review_started",
|
|
|
+ review_round=review_round,
|
|
|
+ report_path=saved_report_path.as_posix(),
|
|
|
+ )
|
|
|
+ review_started_at = time.perf_counter()
|
|
|
+ reviewer_raw_response = str(llm.invoke(reviewer_messages)).strip()
|
|
|
+ review_duration_ms = _elapsed_ms(review_started_at)
|
|
|
+ _accumulate_duration(timing_breakdown, "review_duration_ms", review_duration_ms)
|
|
|
+ _accumulate_duration(timing_breakdown, "llm_duration_ms", review_duration_ms)
|
|
|
+ reviewer_reply = _safe_parse_reviewer_reply(reviewer_raw_response)
|
|
|
+ review_log_path = logs_dir / f"review_round_{review_round}_review.json"
|
|
|
+ saved_review_log_path = _save_review_log(
|
|
|
+ review_log_path=review_log_path,
|
|
|
+ review_round=review_round,
|
|
|
+ reviewer_reply=reviewer_reply,
|
|
|
+ candidate_report_path=saved_report_path,
|
|
|
+ )
|
|
|
+ review_history.append(
|
|
|
+ ReviewRecord(
|
|
|
+ round_index=review_round,
|
|
|
+ decision=reviewer_reply.decision,
|
|
|
+ critique=reviewer_reply.critique,
|
|
|
+ raw_response=reviewer_reply.raw_response,
|
|
|
+ review_log_path=saved_review_log_path,
|
|
|
+ candidate_report_path=saved_report_path,
|
|
|
+ )
|
|
|
+ )
|
|
|
+ review_rounds_used = review_round
|
|
|
+ review_critique = reviewer_reply.critique
|
|
|
+
|
|
|
+ if reviewer_reply.decision == "Accept":
|
|
|
+ review_status = "accepted"
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "review_accepted",
|
|
|
+ review_round=review_round,
|
|
|
+ critique=reviewer_reply.critique,
|
|
|
+ )
|
|
|
+ break
|
|
|
+
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "review_rejected",
|
|
|
+ review_round=review_round,
|
|
|
+ critique=reviewer_reply.critique,
|
|
|
+ )
|
|
|
+
|
|
|
+ review_status = "rejected"
|
|
|
+ if review_round >= total_rounds:
|
|
|
+ review_status = "max_reviews_reached"
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "review_max_reached",
|
|
|
+ review_round=review_round,
|
|
|
+ critique=reviewer_reply.critique,
|
|
|
+ )
|
|
|
+ break
|
|
|
+
|
|
|
+ analyst_messages.append(
|
|
|
+ {
|
|
|
+ "role": "user",
|
|
|
+ "content": (
|
|
|
+ f"[审稿人拒稿意见]:{reviewer_reply.critique}\n"
|
|
|
+ "你必须逐条回应并修复以下全部问题,重新分析并重写报告。"
|
|
|
+ f"下一轮所有新图表必须保存到:{(figures_dir / f'review_round_{review_round + 1}').as_posix()}。"
|
|
|
+ "不要重复原报告中的问题,也不要忽略任何已经指出的主要缺陷。"
|
|
|
+ ),
|
|
|
+ }
|
|
|
+ )
|
|
|
+
|
|
|
+ if report_path is not None:
|
|
|
+ save_markdown_report(report_markdown, Path(report_path))
|
|
|
+
|
|
|
+ step_traces_tuple = tuple(all_step_traces)
|
|
|
+ tools_used = _collect_tools_used(step_traces_tuple, telemetry)
|
|
|
+ search_status, search_notes = _determine_search_status(step_traces_tuple, telemetry)
|
|
|
+
|
|
|
+ timing_snapshot = dict(timing_breakdown)
|
|
|
+ timing_snapshot["total_duration_ms"] = _elapsed_ms(run_started_at)
|
|
|
+
|
|
|
+ final_trace_persist_started_at = time.perf_counter()
|
|
|
+ _save_agent_trace(
|
|
|
+ trace_path=trace_path,
|
|
|
+ runtime_config=runtime_config,
|
|
|
+ data_context=data_context,
|
|
|
+ run_dir=run_dir,
|
|
|
+ max_steps=max_steps,
|
|
|
+ effective_max_steps=effective_max_steps,
|
|
|
+ step_traces=step_traces_tuple,
|
|
|
+ telemetry=telemetry,
|
|
|
+ search_status=search_status,
|
|
|
+ search_notes=search_notes,
|
|
|
+ tools_used=tools_used,
|
|
|
+ artifact_validation=artifact_validation,
|
|
|
+ analysis_rounds=tuple(analysis_rounds),
|
|
|
+ review_history=tuple(review_history),
|
|
|
+ visual_review_history=tuple(visual_review_history),
|
|
|
+ document_ingestion=document_ingestion,
|
|
|
+ review_status=review_status,
|
|
|
+ quality_mode=resolved_quality_mode,
|
|
|
+ latency_mode=resolved_latency_mode,
|
|
|
+ vision_review_mode=resolved_vision_review_mode,
|
|
|
+ review_enabled=review_enabled,
|
|
|
+ search_enabled=search_enabled,
|
|
|
+ fast_path_enabled=fast_path_enabled,
|
|
|
+ small_simple_dataset=small_simple_dataset,
|
|
|
+ vision_configured=runtime_config.vision_configured,
|
|
|
+ timing_breakdown=timing_snapshot,
|
|
|
+ )
|
|
|
+ _accumulate_duration(
|
|
|
+ timing_breakdown,
|
|
|
+ "trace_persist_duration_ms",
|
|
|
+ _elapsed_ms(final_trace_persist_started_at),
|
|
|
+ )
|
|
|
+ final_timing_breakdown = dict(timing_breakdown)
|
|
|
+ final_timing_breakdown["total_duration_ms"] = _elapsed_ms(run_started_at)
|
|
|
+
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "report_saved",
|
|
|
+ report_path=saved_report_path.as_posix(),
|
|
|
+ trace_path=saved_trace_path.as_posix(),
|
|
|
+ tools_used=tools_used,
|
|
|
+ search_status=search_status,
|
|
|
+ telemetry_valid=telemetry.valid,
|
|
|
+ )
|
|
|
+ _emit_event(
|
|
|
+ event_handler,
|
|
|
+ "artifact_validation_completed",
|
|
|
+ workflow_complete=artifact_validation.workflow_complete,
|
|
|
+ missing_artifacts=artifact_validation.missing_artifacts,
|
|
|
+ warnings=artifact_validation.warnings,
|
|
|
+ )
|
|
|
+
|
|
|
+ return AnalysisRunResult(
|
|
|
+ data_context=data_context,
|
|
|
+ raw_result=raw_result,
|
|
|
+ report_markdown=report_markdown,
|
|
|
+ report_path=saved_report_path,
|
|
|
+ output_dir=run_dir,
|
|
|
+ run_dir=run_dir,
|
|
|
+ data_dir=data_dir,
|
|
|
+ figures_dir=figures_dir,
|
|
|
+ logs_dir=logs_dir,
|
|
|
+ trace_path=saved_trace_path,
|
|
|
+ cleaned_data_path=cleaned_data_path,
|
|
|
+ agent_type=current_runner.__class__.__name__ if current_runner is not None else ScientificReActRunner.__name__,
|
|
|
+ step_traces=step_traces_tuple,
|
|
|
+ telemetry=telemetry,
|
|
|
+ methods_used=telemetry.methods,
|
|
|
+ detected_domain=telemetry.domain,
|
|
|
+ tools_used=tools_used,
|
|
|
+ search_status=search_status,
|
|
|
+ search_notes=search_notes,
|
|
|
+ workflow_complete=artifact_validation.workflow_complete,
|
|
|
+ workflow_warnings=artifact_validation.warnings,
|
|
|
+ missing_artifacts=artifact_validation.missing_artifacts,
|
|
|
+ quality_mode=resolved_quality_mode,
|
|
|
+ review_enabled=review_enabled,
|
|
|
+ review_status=review_status,
|
|
|
+ review_rounds_used=review_rounds_used,
|
|
|
+ review_critique=review_critique,
|
|
|
+ review_log_paths=tuple(review.review_log_path for review in review_history),
|
|
|
+ input_kind=document_ingestion.input_kind,
|
|
|
+ document_ingestion_status=document_ingestion.status,
|
|
|
+ document_ingestion_summary=document_ingestion.summary,
|
|
|
+ document_ingestion_duration_ms=final_timing_breakdown.get("document_ingestion_duration_ms", 0),
|
|
|
+ document_ingestion_log_path=document_ingestion.log_path,
|
|
|
+ candidate_table_count=document_ingestion.candidate_table_count,
|
|
|
+ selected_table_id=document_ingestion.selected_table_id,
|
|
|
+ selected_table_shape=document_ingestion.selected_table_shape,
|
|
|
+ pdf_multi_table_mode=document_ingestion.pdf_multi_table_mode,
|
|
|
+ latency_mode=resolved_latency_mode,
|
|
|
+ vision_review_mode=resolved_vision_review_mode,
|
|
|
+ vision_review_enabled=visual_attempt_enabled if review_enabled else False,
|
|
|
+ vision_review_status=vision_review_status,
|
|
|
+ vision_review_summary=vision_review_summary,
|
|
|
+ vision_review_duration_ms=final_timing_breakdown.get("vision_review_duration_ms", 0),
|
|
|
+ vision_review_log_paths=tuple(review.log_path for review in visual_review_history),
|
|
|
+ total_duration_ms=final_timing_breakdown.get("total_duration_ms", 0),
|
|
|
+ llm_duration_ms=final_timing_breakdown.get("llm_duration_ms", 0),
|
|
|
+ tool_duration_ms=final_timing_breakdown.get("tool_duration_ms", 0),
|
|
|
+ review_duration_ms=final_timing_breakdown.get("review_duration_ms", 0),
|
|
|
+ timing_breakdown=final_timing_breakdown,
|
|
|
+ )
|

 captain
captain
{kind=link}
{kind=link}
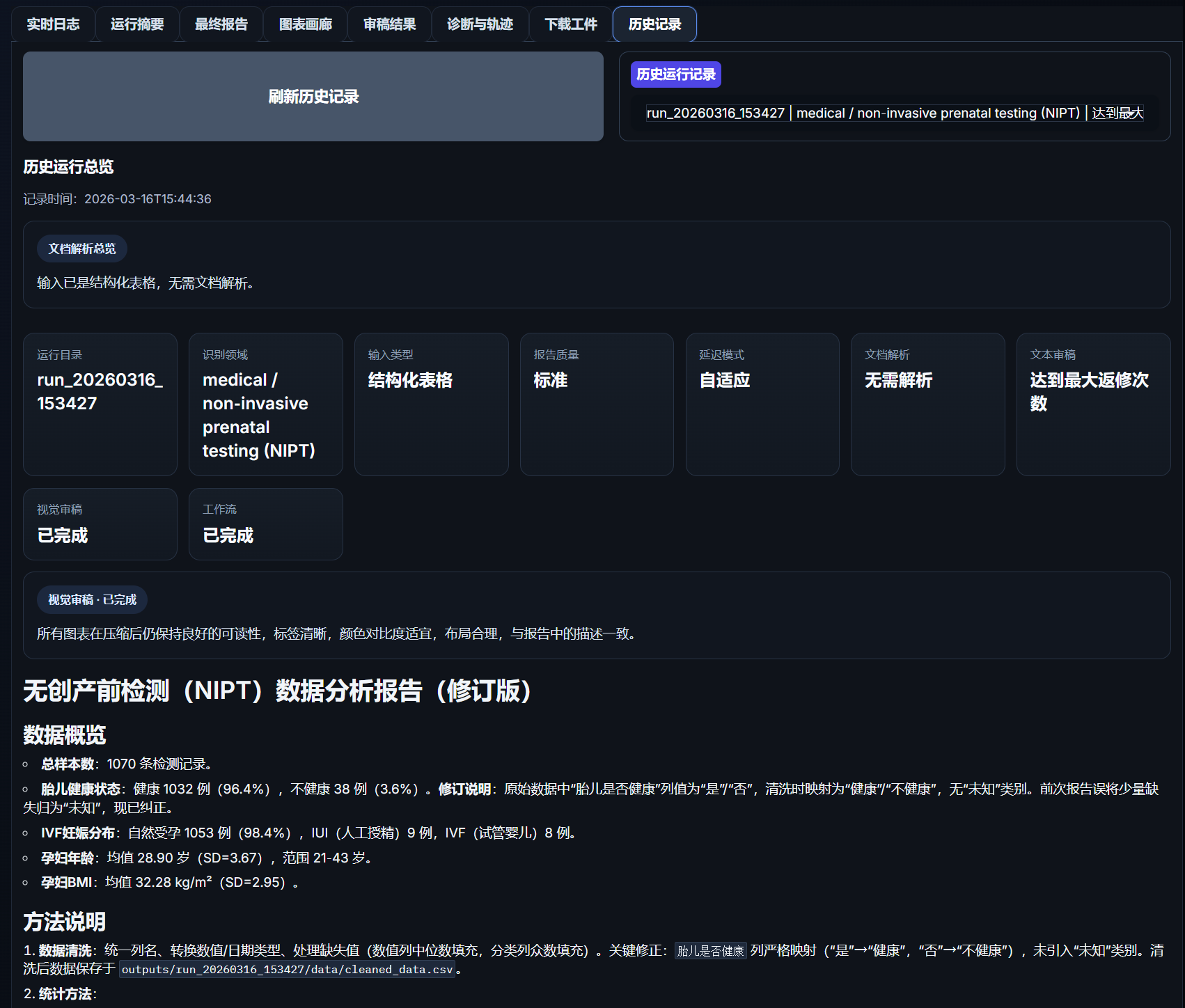
{kind=link}